A Geometric Diagnostic for Routing Discontinuity in Released Weights — Zhuo Zhang, Independent Researcher · 📄 Read the full paper (PDF) →
A companion to DeepSeek V4 and Manifold Tearing. That post was the argument — loss spikes are geometric tears, not optimization blowups. This one is the measurement: I built a diagnostic, pointed it at released MoE weights, and asked how torn they actually are. This write-up is the readable version; the PDF carries the full method, related-work, and reproducibility appendices.
In the DeepSeek post I borrowed a word from Max Ma and Gen-Hua Shi's Deep Manifold framework: a Mixture-of-Experts layer doesn't bend the representation, it can tear it. Bending is continuous and benign; tearing is discrete and the pathology. It was a good story. But a metaphor is a debt — at some point you have to show the tear exists, say how big it is, and admit what it does and doesn't cause.
So I paid the debt. What follows is a measurement paper compressed into a blog post: a geometric diagnostic, run on released OLMoE and Qwen weights, with negative controls and known-answer tests.
A metaphor I owed a measurement
A MoE layer routes each token to a small top- subset of experts. That discrete choice makes the layer-to-layer map -discontinuous: two hidden states arbitrarily close, but on opposite sides of a routing boundary, go to different experts — so the block output can jump by an amount. That jump is the tear.
Prior work approaches this from two sides and stops short of measuring it on real models:
- Continuous-routing fixes — ReMoE replaces top- with ReLU routing and explicitly frames top- as a jump discontinuity; Soft MoE and sparsemax/α-entmax are relatives. These remove the discontinuity; they don't quantify the one sitting in shipped weights.
- Routing flip-rate — the R3 router-replay study reports that ≈10% of routers and 94% of tokens flip at least one expert between the training and inference engines. That counts how often the expert set changes, not the output jump the change induces.
Nobody had measured the quantity that actually governs the transport map on a real model: the output-jump geometry on released LLM-MoE weights — how big the jump is, where it sits, and which direction triggers it. That's the gap.
What a tear actually is
A MoE block maps to
with router logits , top- selecting the largest, and the renormalized softmax over the selected logits. Order the logits . The active-set boundary is where
a hyperplane with normal . Cross it and you swap the -th expert, jumping the block output by . That is a genuine discontinuity — contrast a ReLU MLP, which is -continuous with kinks.
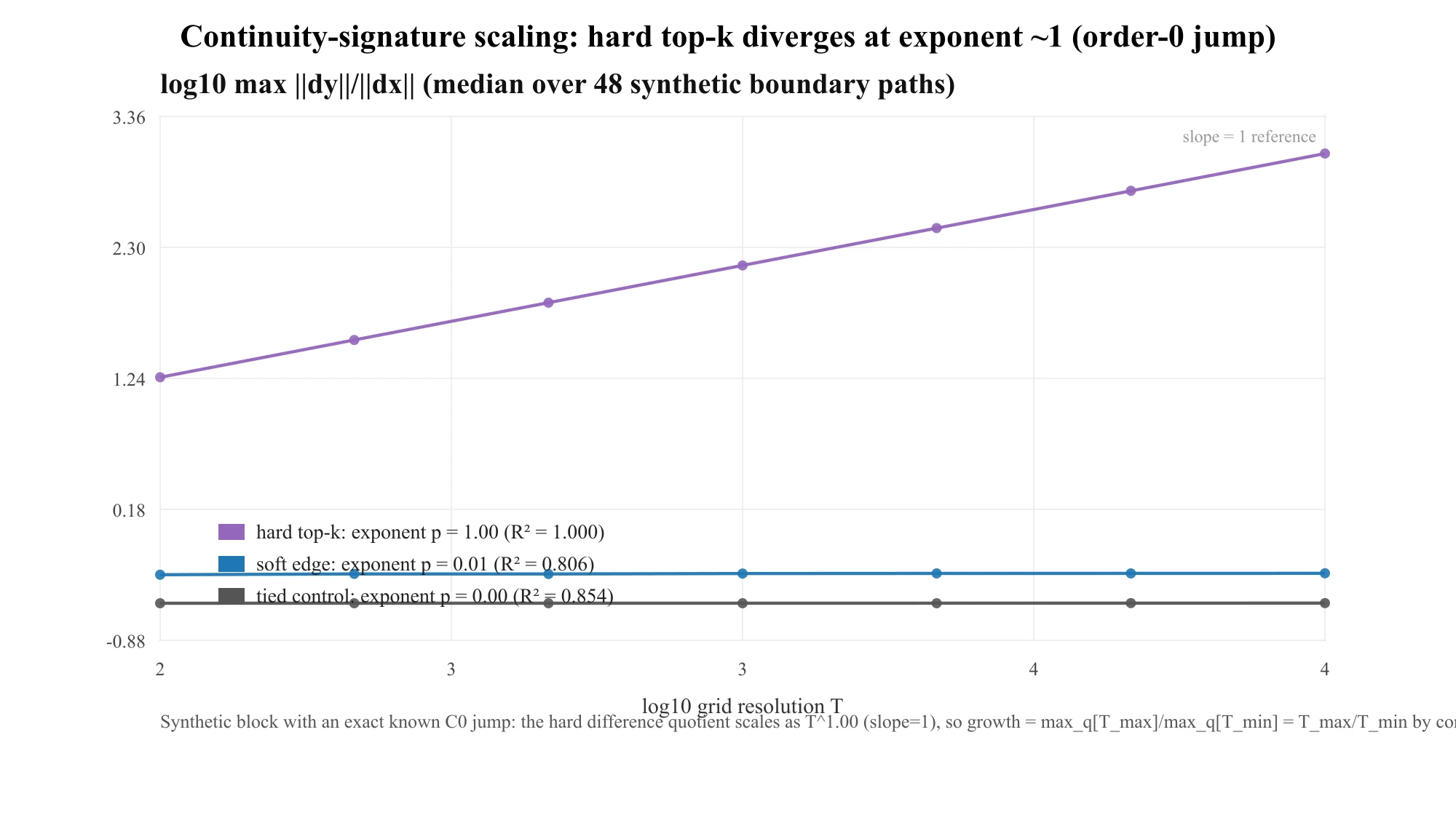
The instrument is a difference quotient: walk a path that crosses the boundary, measure , and refine the grid — I sample it at resolutions . For a continuous map the quotient saturates; for a genuine order-0 jump it grows linearly in the resolution, as . The tell is the scaling exponent: for a jump, for a continuous map.
Here is the part that's easy to misread, so let me be blunt about it. I summarize that growth as hardG = (max quotient at 8000) / (max quotient at 500). For any nonzero jump that ratio is — by construction — just the grid ratio , independent of , the expert count, or the layer. So 16× is not a severity. It is the number a true order-0 jump must produce under this protocol; it certifies "the singularity is order-0, and it's here," and nothing more. Larger would not be worse — there is no "larger." The actual severity lives elsewhere: in the per-block output jump and the expert cliff, both below. Two negative controls keep the instrument honest — a tied-expert control (the swap is a no-op) and a continuity-guaranteed soft-edge gate — both required to sit at exponent ().
A synthetic block with an exact, known jump nails the law down: the hard difference quotient scales as (fitted exponent 1.0005, across resolutions ), while the controls stay flat. That is the known-answer test — it confirms the released-weight 16× is the order-0 signature, not a probe artifact, and explains why it is pinned across layers, models, and .
Three core measurements come out of this:
- M1 — boundary prevalence: the distribution of the margin and the fraction of tokens sitting near the boundary.
- M2 — expert cliff: the normalized , plus the cosine of the swapped pair. cos ≈ 1 means redundant (no real tear); cos ≈ 0 means non-redundant at the baseline; cos < 0 means genuinely specialized. This separates "outsized specialization" from "merely non-redundant."
- M3 — continuity signature: the scaling exponent above (≈1 for a jump, ≈0 for a continuous map), summarized as hardG, with its two controls.
Severity, then, is not in the continuity signature. It is carried by the per-block jump and M2 — keep that split in mind for everything below.
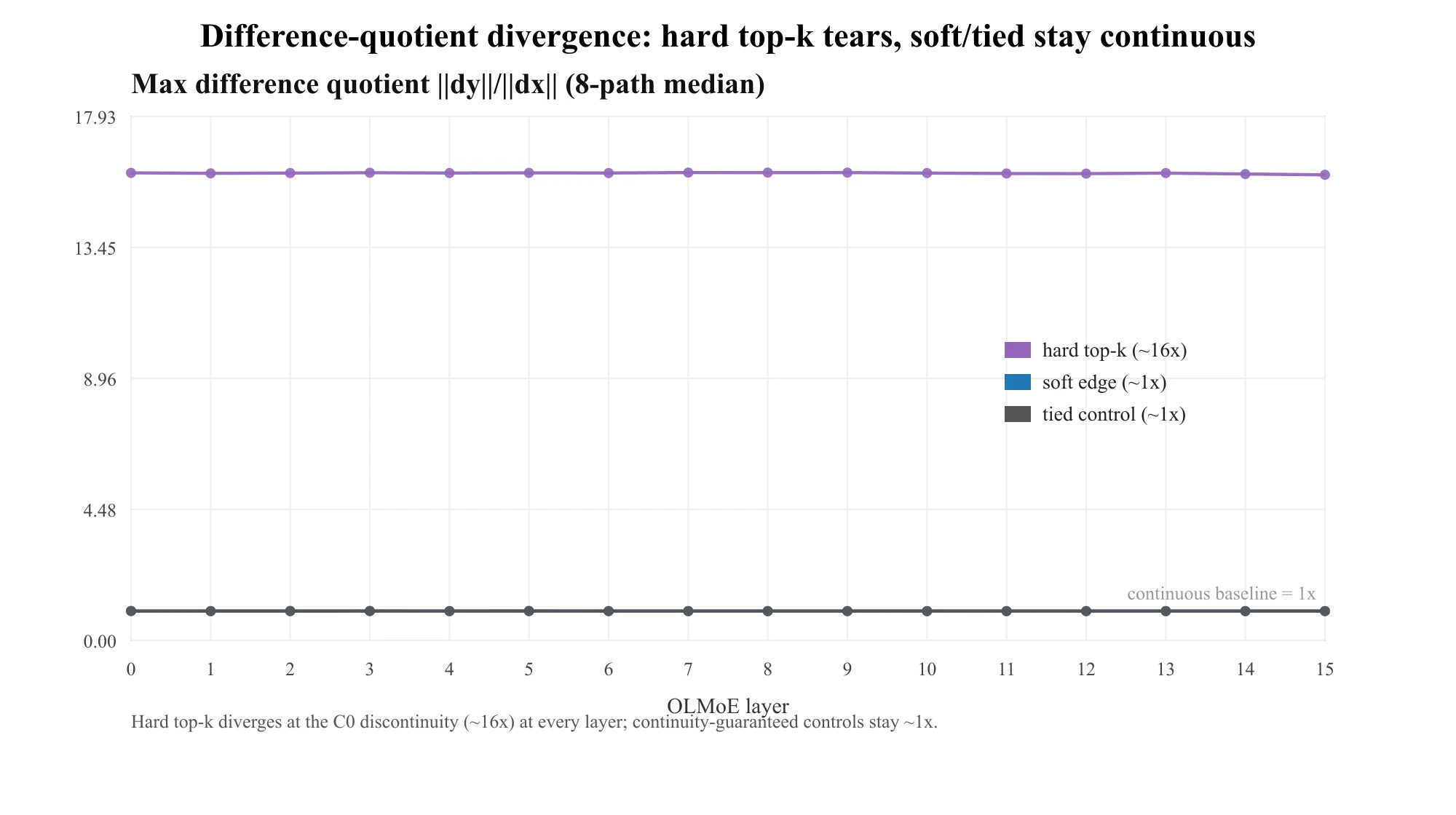
The result: released routers are torn at every layer
The tear is not synthetic. On OLMoE-1B-7B (16 layers, 64 experts, ), the continuity signature is a genuine order-0 jump at every layer — refinement growth hardG (scaling exponent 1.00, range 15.93–16.01), the difference quotient diverging at the grid-refinement rate — while both controls stay pinned at exponent (). That's the headline figure at the top of this post. As established above, the 16× is the grid ratio any true jump reaches, not a severity. The severity is two other numbers: the per-block output jump — about 24% of the block-output norm (a per-block geometric quantity, not a change in the model's output, logits, or task accuracy) — and the expert cliff M2 , cosine , right at the unrelated-vector baseline (non-redundant, but not outsized specialization). Near-boundary fraction is (median margin ).
Table 1 — OLMoE-1B-7B per-layer diagnostic (24 texts). hardG is the refinement growth (max@8000 / max@500); for an order-0 jump it equals the grid ratio 16, i.e. exponent ≈1.00 — its near-constancy is the protocol's, not the model's. The block-jump column is the per-block output jump (fraction of block-output norm). hardG, block jump, and the two controls are medians over 8 boundary-crossing refinement paths; margin, M2, cos are per-token medians. Across layers: median hardG 15.99× (exponent 1.00), M2 0.704, cos 0.025; mean block jump 0.239; soft/tied controls ≈1.00.
| Layer | margin | M2 cliff | cos | hardG | block jump | soft ctl | tied ctl |
|---|---|---|---|---|---|---|---|
| 0 | 0.0012 | 0.694 | 0.056 | 16.00 | 0.238 | 1.005 | 1.001 |
| 1 | 0.0009 | 0.701 | 0.033 | 15.98 | 0.309 | 1.003 | 1.002 |
| 2 | 0.0010 | 0.702 | 0.028 | 15.99 | 0.246 | 1.004 | 1.001 |
| 3 | 0.0011 | 0.704 | 0.022 | 16.00 | 0.248 | 1.004 | 1.002 |
| 4 | 0.0011 | 0.703 | 0.025 | 15.99 | 0.282 | 1.003 | 1.002 |
| 5 | 0.0012 | 0.702 | 0.030 | 16.00 | 0.288 | 1.004 | 1.002 |
| 6 | 0.0011 | 0.704 | 0.023 | 15.99 | 0.284 | 1.002 | 1.003 |
| 7 | 0.0014 | 0.704 | 0.026 | 16.01 | 0.233 | 1.003 | 1.002 |
| 8 | 0.0015 | 0.704 | 0.025 | 16.00 | 0.249 | 1.003 | 1.002 |
| 9 | 0.0019 | 0.703 | 0.026 | 16.01 | 0.266 | 1.003 | 1.002 |
| 10 | 0.0019 | 0.708 | 0.015 | 15.99 | 0.212 | 1.003 | 1.002 |
| 11 | 0.0021 | 0.709 | 0.012 | 15.98 | 0.244 | 1.003 | 1.002 |
| 12 | 0.0026 | 0.707 | 0.021 | 15.97 | 0.226 | 1.003 | 1.002 |
| 13 | 0.0023 | 0.709 | 0.015 | 15.99 | 0.157 | 1.003 | 1.002 |
| 14 | 0.0023 | 0.703 | 0.035 | 15.96 | 0.222 | 1.003 | 1.002 |
| 15 | 0.0028 | 0.600 | 0.301 | 15.93 | 0.123 | 1.003 | 1.002 |
Layer 15 (the last block) is the lone mild outlier — a lower cliff (M2 0.60) and higher cosine (0.30 → more expert redundancy) — yet its discontinuity (hardG 15.93×) is undiminished.
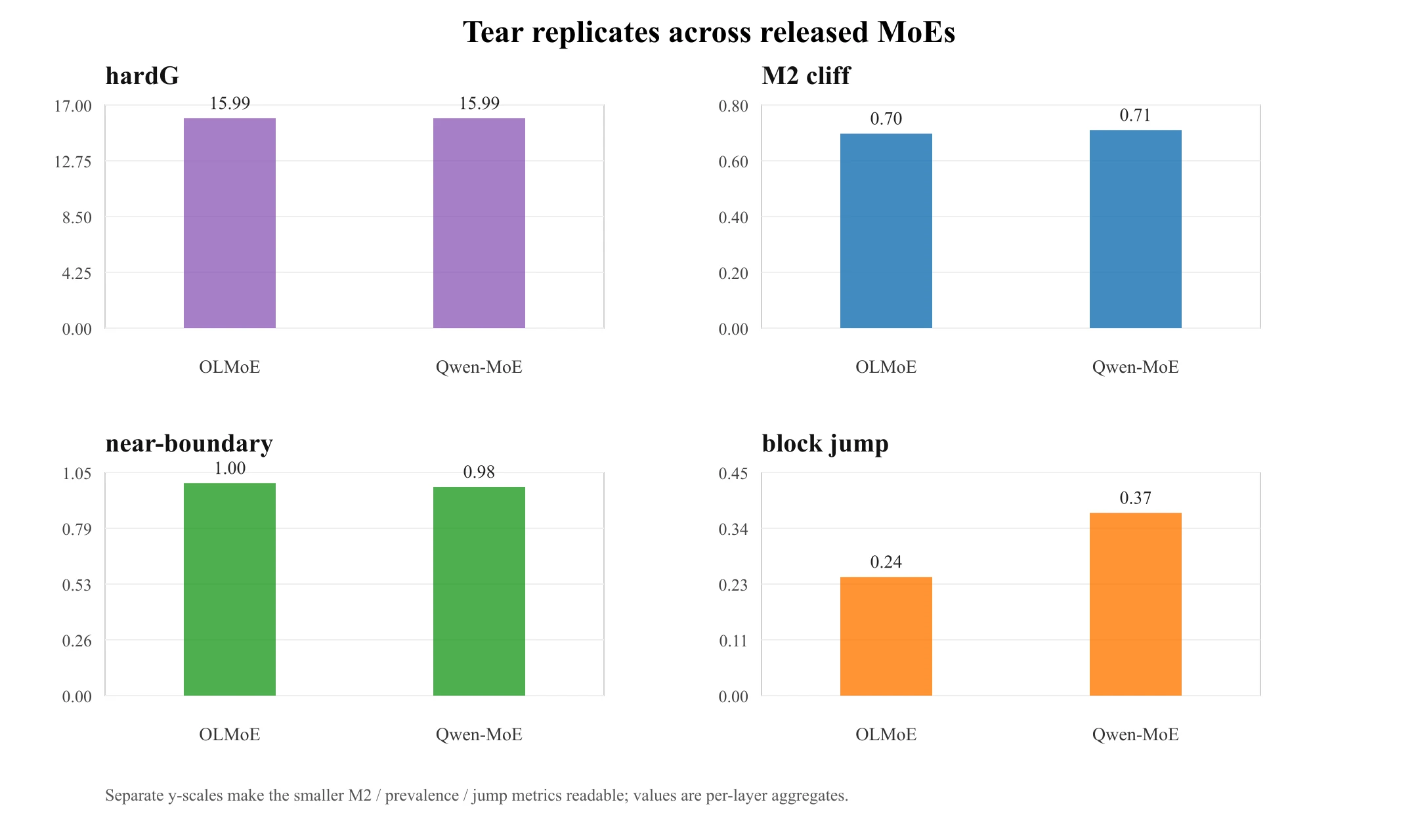
This is not an OLMoE quirk. Qwen1.5-MoE-A2.7B (24 layers, 60 routed experts, ) reproduces the same pattern:
| metric | OLMoE | Qwen1.5-MoE |
|---|---|---|
| hardG (continuity signature) | ≈16× all layers | 15.99× (15.96–16.02) |
| M2 expert cliff | ≈0.70 | 0.710 |
| ≈0.025 | 0.010 | |
| near-boundary fraction (margin < 0.05) | ≈100% | 98.2% |
| whole-block jump | ≈0.239 | 0.368 |
| tied / soft control | ≈1.0× | 1.002× / 1.003× |
Is the 16× just an artifact of ? No — and there are two reasons before you even run another experiment. (i) By construction, the refinement growth equals the grid ratio 8000/500 for any nonzero jump, regardless of ; there is no algebraic path from to 16. (ii) Qwen routes and lands on the same growth (15.99×, exponent 1.00) as OLMoE's — exactly what you'd expect if 16 is the protocol's grid ratio, and not what you'd expect if it were set by . (A direct sweep would settle it outright; I leave that as future strengthening.)
The one-line summary: training does not sew up the seam. Released routers carry the order-0 discontinuity (exponent ≈1) at every layer — with the per-block jump real at ≈24% and the cliff M2 ≈ 0.70 sitting at the unrelated-vector baseline — on both families.
The tear is directional — and that's the surprising part
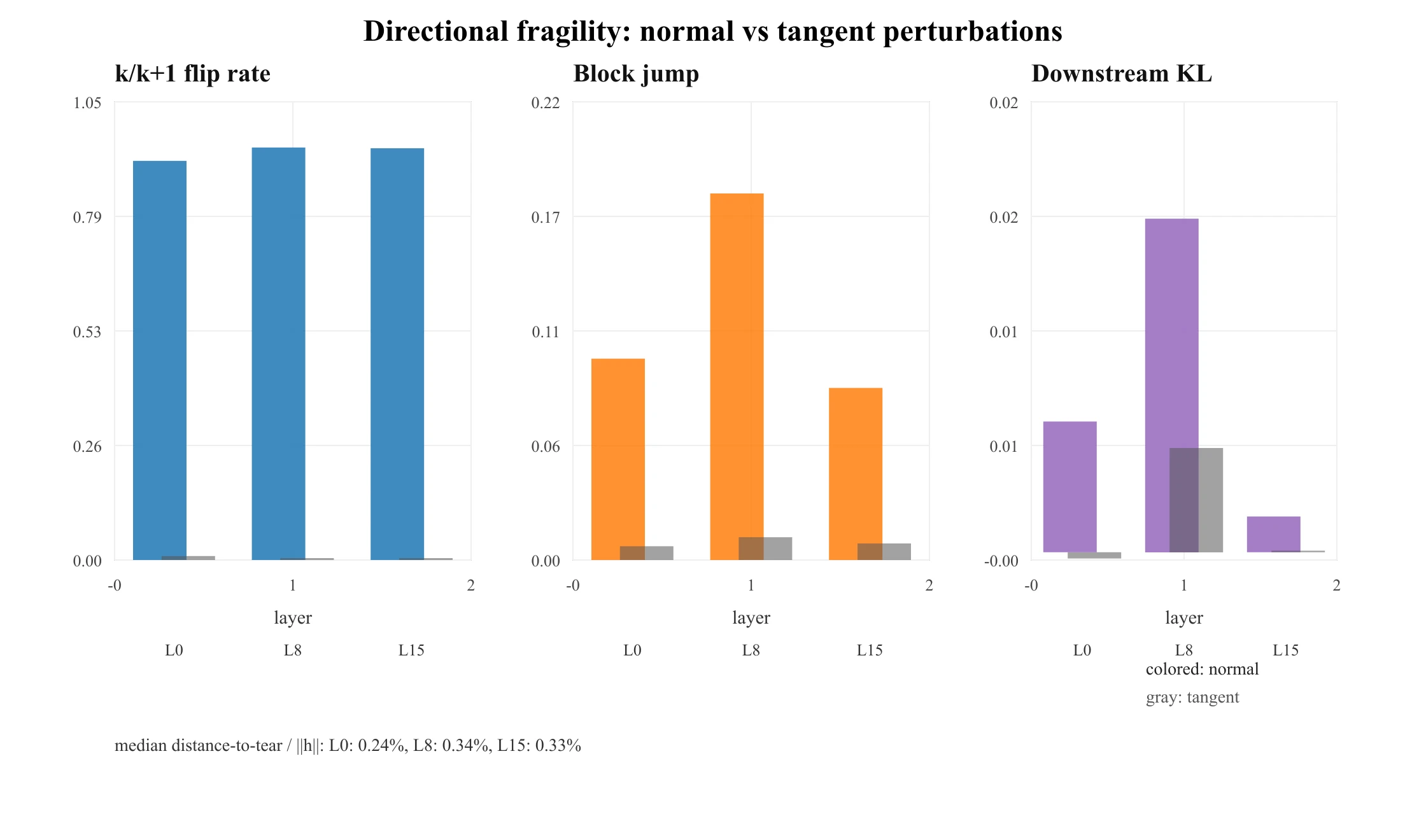
Here is where the naive intuition fails. The obvious robustness test is: perturb the hidden state randomly and see if removing the tear makes the block more stable. The answer is a null — and the null is informative.
Even at a perturbation large enough to flip 67.6% of tokens' top- sets, the hard-vs-soft block jump differs by only 2.6% (0.581 vs 0.566). Killing the tear barely changes the block's response to random noise. The null isn't that experts never flip — at this magnitude 67.6% of them do — it's that random flips add almost no discontinuous excess on top of the smooth response the soft gate already produces.
The reason is geometric: random perturbations are almost always tangent to the boundary. Perturb along the raw-logit boundary normal instead, at the per-token distance-to-tear, and the picture inverts:
| OLMoE layer | normal flip | tangent flip | normal jump | tangent jump | normal ΔKL | tangent ΔKL |
|---|---|---|---|---|---|---|
| 0 | 0.915 | 0.009 | 0.098 | 0.0067 | 0.0063 | −0.0003 |
| 8 | 0.945 | 0.004 | 0.179 | 0.0111 | 0.0161 | 0.0050 |
| 15 | 0.944 | 0.004 | 0.084 | 0.0081 | 0.0017 | 0.0001 |
The distance-to-tear is tiny — median 0.24–0.34% of — so the model lives on the boundary. A boundary-normal nudge of under 1% relative magnitude flips the expert ( probability) and produces an per-block output jump (a fraction of the block-output norm, not the model output) with measurable downstream KL, while an equal-magnitude random/tangent nudge does next to nothing. The tear is exploitable, but only along a specific low-dimensional direction.
And you can't cheaply re-gate it away. Continuous re-gating removes the static tear (softG ), but applied to all layers at inference it raises perplexity 10.04 → 159.94 (15.9×) at the gentlest threshold. Single-layer re-gating is mild (). So a practical mitigation has to be layer-targeted — or, as DeepSeek-V4 does, folded into training rather than bolted on afterward.
Training: it decomposes, it doesn't detonate
This is the honest negative, and it's the part that keeps the metaphor from overreaching. To probe training I used a controlled from-scratch GPT-MoE probe at OLMoE-like geometry (E=64, k=8, ≈308M params) — not the 7B model's pretraining.
Mechanism (real, modest): a parameter-space difference-quotient probe finds hard routing rougher than a continuity-matched soft gate — 2.0× vs 1.4×. Directionally consistent with the synthetic 4.5×, but weaker as the geometry becomes realistic.
Outcome: natural training is spiky-but-convergent, and the tear does not self-heal. Over 8000 steps there are 196 spikes >0.3 (max 0.585) yet no divergence (final loss 3.27). M2 holds 0.711 → 0.690 and hardG stays throughout, while the operational whole-block jump collapses early (0.431 → ≈0.15) then sits in a noisy band. Training suppresses the tear's consequence, not its topology.
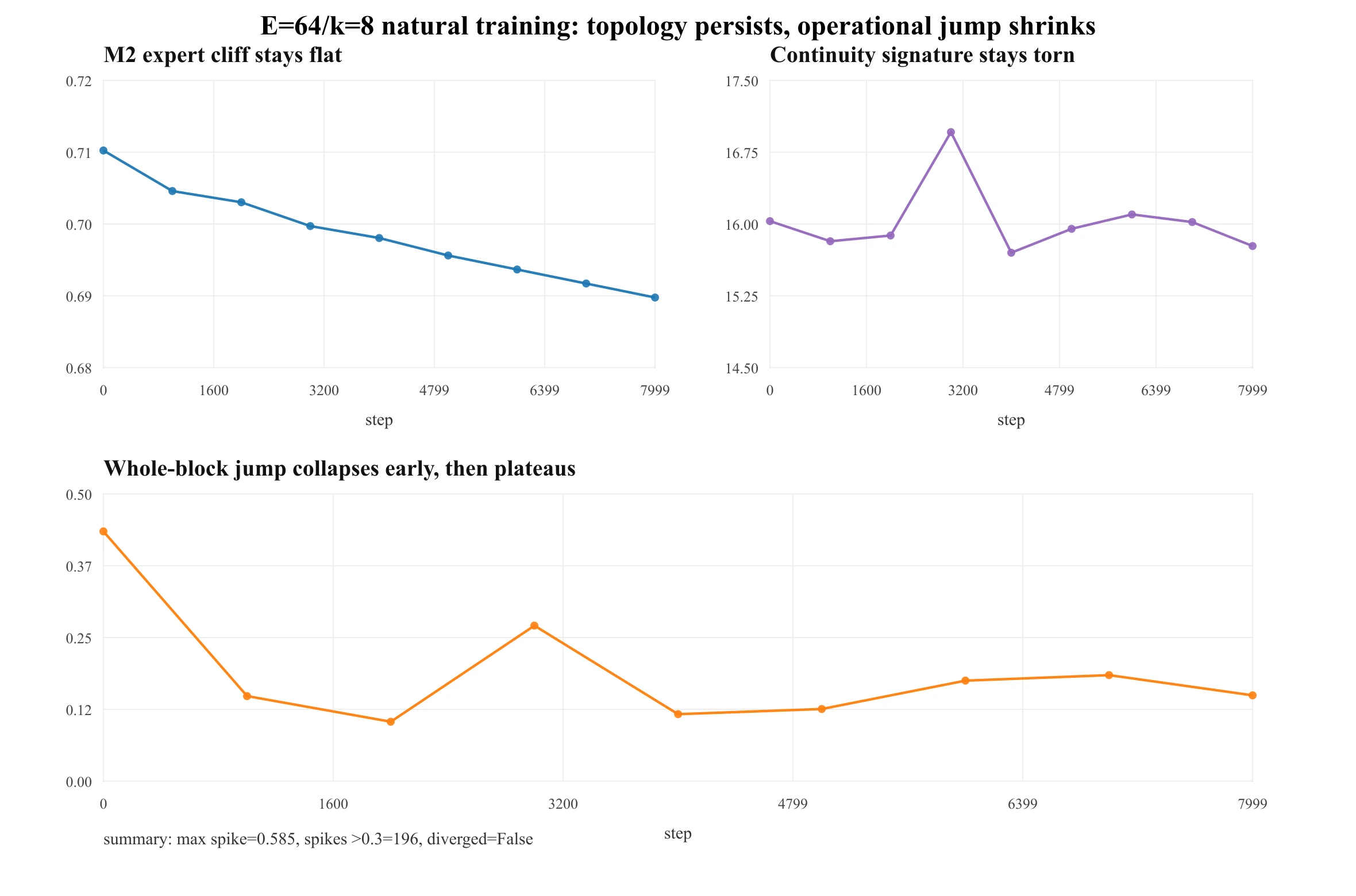
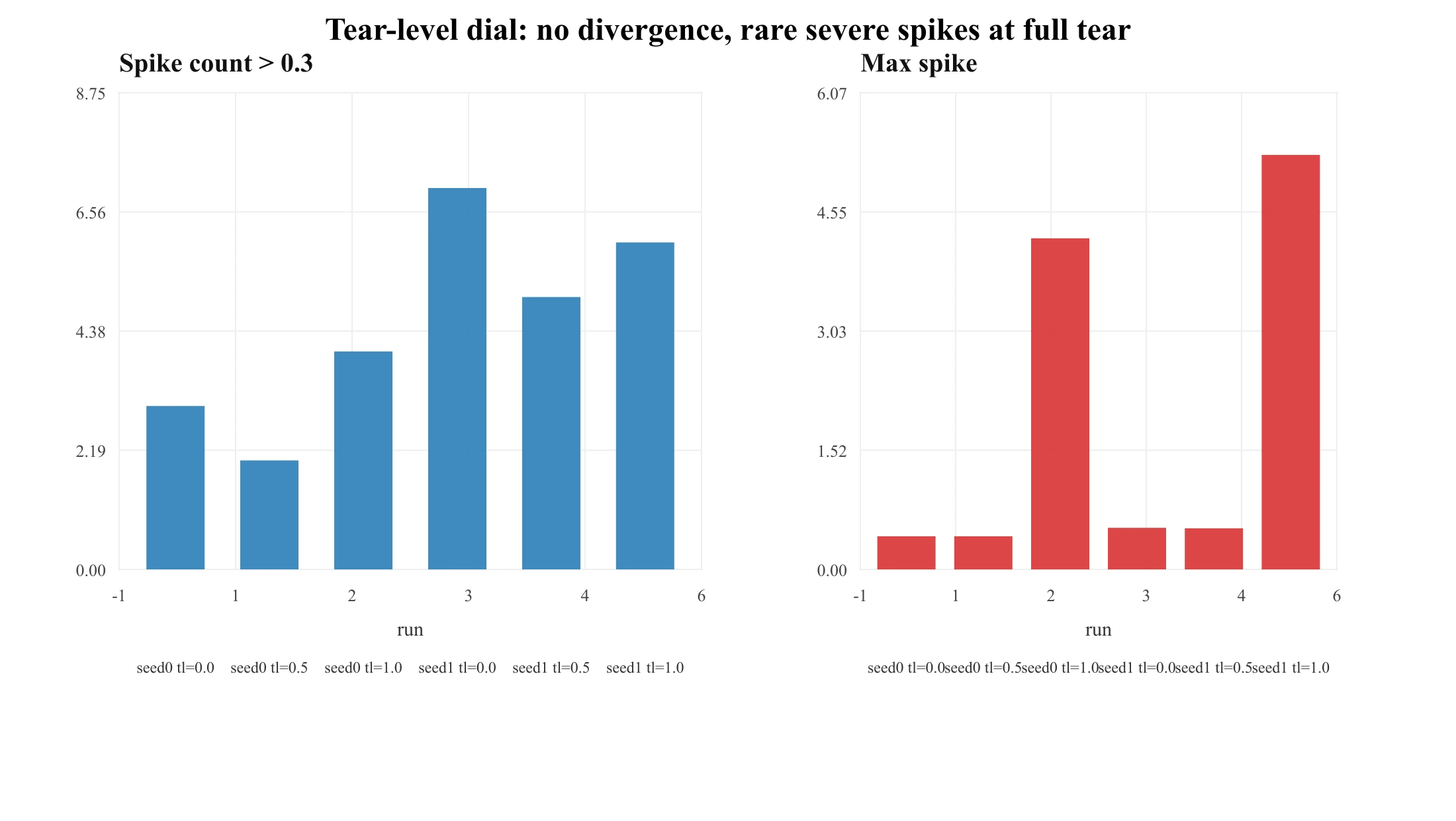
Push harder with a tear-magnitude dial across two seeds at the edge of stability:
| seed | tear_level | spikes >0.3 | max spike | diverged |
|---|---|---|---|---|
| 0 | 0.0 / 0.5 / 1.0 | 3 / 2 / 4 | 0.42 / 0.42 / 4.21 | no / no / no |
| 1 | 0.0 / 0.5 / 1.0 | 7 / 5 / 6 | 0.53 / 0.52 / 5.28 | no / no / no |
No run diverges. Spike count isn't even monotone in tear level. But full tear reproducibly seeds a rare severe-but-recovered spike (max ≈4–5 vs ≈0.5). The honest statement: the tear contributes optimization roughness and rare spike severity, but is not by itself sufficient for collapse at this scale — momentum and Adam absorb it. Scale-dependence stays open, and that's exactly where DeepSeek-V4's engineering becomes relevant.
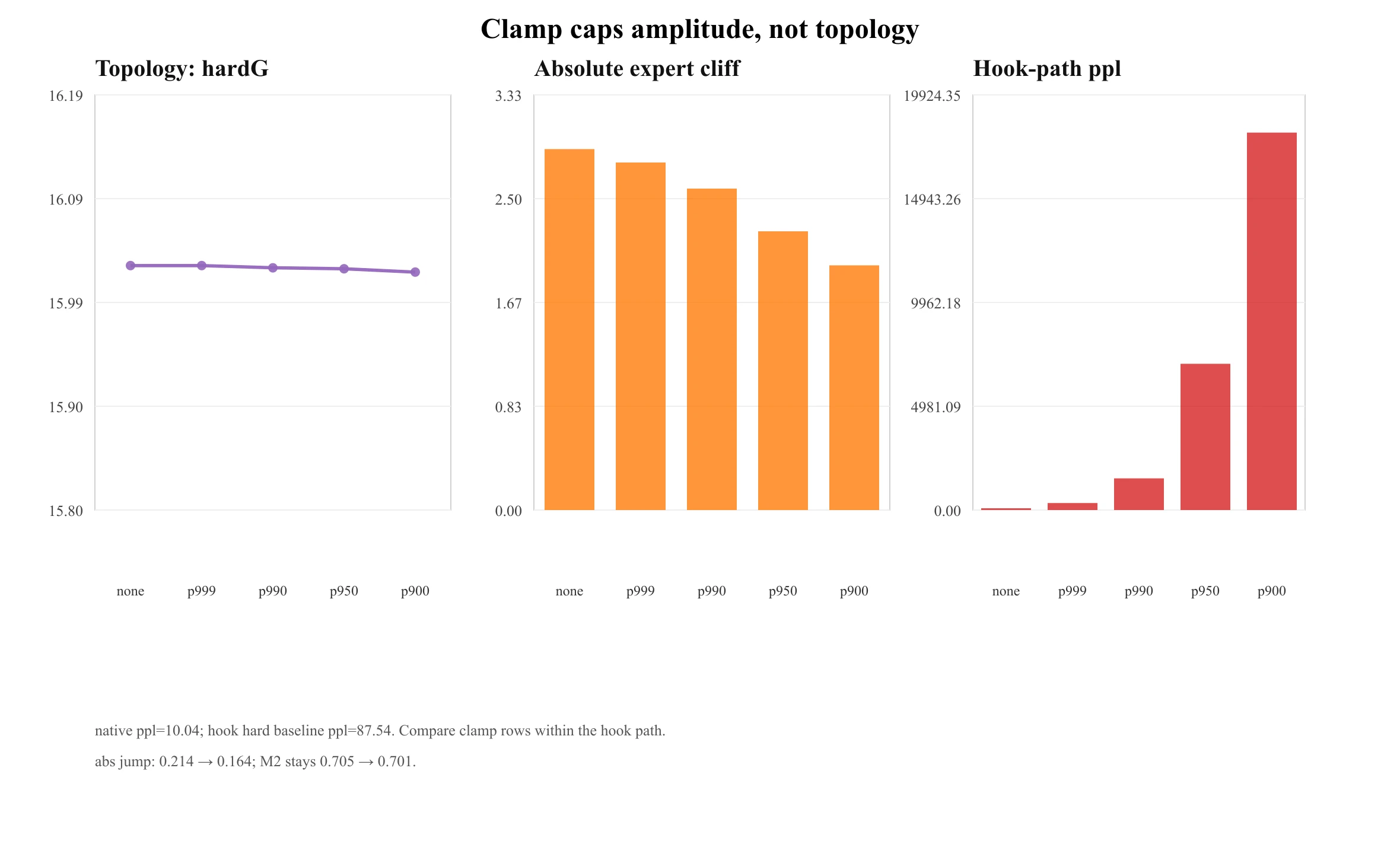
Reading DeepSeek-V4's three defenses geometrically
This is where it closes back on the DeepSeek post. The key caution: routing discontinuity is not loss spike. The discontinuity is the first of several separable factors:
- Routing discontinuity — directional, the geometric entry point (§ above).
- Expert-outlier magnitude — the jump scales with it; I measure the correlation between and the -swap jump at +0.437 (high-norm tokens jump more).
- Temporal backbone/router mismatch — untested here (future work).
- Cross-layer propagation gain — downstream-KL / injected-jump (a non-expansive residual bounds it).
- Optimizer absorption — the training result above.
DeepSeek-V4's three interventions map cleanly onto factors 2–4 — they control the consequences, not the topology: SwiGLU clamping (factor 2), Anticipatory Routing (factor 3), and manifold-constrained hyper-connections (factor 4 — a residual map on the Birkhoff polytope, spectral norm ≤ 1, non-expansive).
I can verify the first one directly. A SwiGLU-clamp sweep on released OLMoE leaves the topology flat — hardG 16.03 → 16.02, M2 0.705 → 0.701 — while reducing absolute amplitude (expert cliff 2.90 → 1.97, absolute hardJump 0.214 → 0.164); the relative jump stays scale-invariant (0.310 → 0.303). Clamp caps the jump's amplitude, not its existence — the DeepSeek decomposition, measured rather than asserted.
In the DeepSeek post I drew this table, arguing V4's four mechanisms all do the same kind of thing in different positions — admit that weights and activations are geometric objects:
| Layer | Mechanism | Geometric move |
|---|---|---|
| Optimizer | Muon | Project updates onto the isometry group |
| Routing | Anticipatory Routing | Decide in the source-point geometry |
| Forward residual | mHC | Constrain residual to the Birkhoff polytope (non-expansive) |
| Activation | SwiGLU clamping | Bound curvature |
The measurement here says the geometry those mechanisms respect is genuinely there, in the shipped weights — a true order-0 discontinuity at every layer — whether or not the optimizer ever happened to trip over it during training.
What this is, and what it isn't
This is a measurement/analysis result, and I want to be precise about its boundaries:
- It does not propose a new gate, a new taxonomy, or claim first discovery of the discontinuity. ReMoE, Puigcerver et al. (2022), and the spline-theory line own those.
- What it adds: a diagnostic that runs on released weights with negative controls and known-answer tests; a cross-model characterization (OLMoE + Qwen); a directional inference result with a mitigation bound; and an honest training-time decomposition that refuses to overclaim.
The bottom line: the MoE routing tear is real, measurable, and cross-model — a genuine jump (the difference quotient diverges at scaling exponent ≈1 at every layer, controls flat at ≈0) that trained routers carry rather than sew up. It is severe in the per-block output jump (≈24% of the block-output norm) — not in the diagnostic's 16× (that's the grid ratio, not a magnitude), and not in expert specialization (M2 sits at the unrelated-vector baseline). Its inference consequence is directional: random inputs miss it, boundary-normal inputs of under 1% magnitude hit it, and you can't re-gate it away post-hoc for free. Its training role is a decomposition, not a single cause — which is precisely why the engineering remedies cap amplitude rather than remove the tear.
The DeepSeek post argued that treating the network as a geometric object is moving from philosophical stance to engineering default. This one supplies the number that the stance was missing.
Caveats, stated plainly. The continuity signature certifies the order of the singularity (exponent ≈1 vs controls ≈0) and where it sits — it does not measure severity; its 16× growth is the grid ratio any genuine jump must produce, not a model property and not larger-is-worse. Every number here is a geometric quantity on hidden states: the ≈24% block jump and the boundary-normal fragility are not tied to end-to-end task accuracy (GSM8K, MMLU), and the jump is measured one layer at a time, so how tears compound across stacked blocks is untested. Beyond that: two model families and 24 short prompts; a small-scale 308M training probe (the spike-severity signal may be scale-dependent); a single-path hardJump trace (multi-path resampling would give error bars); clamp quality measured within a hook path; the temporal-mismatch factor named but not measured. Deep Manifold (Ma & Shi) is used as motivation only — external prior work, not my own framework. The numeric source of truth is a result-JSON set; every figure regenerates from it with a stdlib-only SVG script.
References
The full method and reproducibility appendices are in the paper PDF.
- Ziteng Wang, Jun Zhu, Jianfei Chen. ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing. ICLR 2025. arXiv:2412.14711
- Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby. From Sparse to Soft Mixtures of Experts. ICLR 2024. arXiv:2308.00951
- André F. T. Martins, Ramón Fernandez Astudillo. From Softmax to Sparsemax. ICML 2016. arXiv:1602.02068
- Ben Peters, Vlad Niculae, André F. T. Martins. Sparse Sequence-to-Sequence Models. ACL 2019. arXiv:1905.05702
- Joan Puigcerver, Rodolphe Jenatton, Carlos Riquelme, Pranjal Awasthi, Srinadh Bhojanapalli. On the Adversarial Robustness of Mixture of Experts. NeurIPS 2022. arXiv:2210.10253
- Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, Fuli Luo. Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers (R3). 2025. arXiv:2510.11370
- Boris Hanin, David Rolnick. Complexity of Linear Regions in Deep Networks. ICML 2019. arXiv:1901.09021
- Randall Balestriero, Richard Baraniuk. A Spline Theory of Deep Networks. ICML 2018. arXiv:1805.06576
- Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, Yoshua Bengio. On the Number of Linear Regions of Deep Neural Networks. NeurIPS 2014. arXiv:1402.1869
- William Fedus, Barret Zoph, Noam Shazeer. Switch Transformers. JMLR 2022. arXiv:2101.03961
- Barret Zoph et al. ST-MoE: Designing Stable and Transferable Sparse Expert Models. 2022. arXiv:2202.08906
- Dmitry Lepikhin et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. ICLR 2021. arXiv:2006.16668
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. 2026. arXiv:2606.19348
- Max Y. Ma, Gen-Hua Shi. Deep Manifold Part 1: Anatomy of Neural Network Manifold. 2024. arXiv:2409.17592
- Max Y. Ma, Gen-Hua Shi. Deep Manifold Part 2: Neural Network Mathematics. 2025. arXiv:2512.06563
- Niklas Muennighoff et al. OLMoE: Open Mixture-of-Experts Language Models. 2024. arXiv:2409.02060
- Qwen Team. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters. 2024. Model blog
Related: DeepSeek V4 and Manifold Tearing · The Four Realms of Neural Networks