This post is adapted from a Bilibili conversation I recorded with Max Ma — Deep Manifold Talks (1) — DeepSeek V4 and Manifold Tearing — drawing heavily on Max Ma's Single-Token Geometry: DeepSeek V4 on Deep Manifold. The video is the accessible version; Max Ma's piece is the mathematical one. This post connects both back to the "manifold prior" I argued for in The Four Realms of Neural Networks.
Anyone who has trained a large model has seen this scene: the loss curve drops smoothly and reassuringly, then suddenly one step shoots through the ceiling, slowly drifts back down, and leaves you with a question you don't quite know how to answer — should I rerun?
The engineering term is loss spike.
The classical story blames optimization: learning rate too high, batch went sideways, some token's gradient blew up. The community's standard treatment follows: clip the gradient, dial the LR back, restart from a checkpoint. The symptom is suppressed; the cause is left unexamined.
DeepSeek V4's tech report, plus the geometric reading, offers a different account:
Loss spikes are not optimization failures; they are manifold tears — topological events caused by discrete routing decisions inconsistent with the local geometry.
If that holds, then V4's mHC, Anticipatory Routing, and SwiGLU clamping aren't isolated tricks. They are three patches on the same geometric problem.
1. Training a large model is an inverse problem
Lift the camera one level.
A bridge engineer with the design, materials, and load can compute whether the bridge will fail — that's a forward problem: structure given, find the result.
Training a large model is the opposite. We see data, text, and answers; we have to reverse-engineer an internal structure that could generate them. That's the textbook inverse problem.
Two things make it hard:
- You don't know what the target structure looks like.
- Your "solver" (the model) doesn't have a stable internal structure to begin with — it shapes itself while it solves.
That's why training large models has stayed a craft: optimizers are tried, learning rates are tried, layer counts, expert counts, router designs — all of it tried. It isn't that engineers don't want theory. It's that the thing under analysis is a moving, half-formed, high-dimensional structure feeling its way through itself.
Once you accept that, loss spike is a geometric event, not an optimization event becomes easier to swallow. In a process that solves while it shapes, the structure itself can break — not just the step size used to chase it.
2. A manifold is not a bend; a tear is not a deformation
"Manifold" sounds abstract; the fastest way in is the Earth. From space it is a sphere; standing on it, the ground under your feet looks flat. Globally curved, locally regular — that is a manifold.
The analogy carries to large models. Data isn't sprinkled uniformly across high-dimensional space; it sits on some complicated structure. Each layer reorganizes the representation, with the goal of "flattening" a tangled high-dimensional structure into something linearly separable. Olah's 2014 Neural Networks, Manifolds, and Topology is still the cleanest visualization.
The key distinction is bend vs. tear:
- Bending is continuous deformation. A mountain road can be steep, but it is still connected — your map still works.
- Tearing is a discontinuous jump. Two formerly adjacent points get sent to disjoint regions. The map has a slit in it.
Max Ma turned "tear" into a precise definition:
A manifold tear is a discontinuity in the layer-to-layer transport map, induced by a discrete routing decision inconsistent with the local geometry.
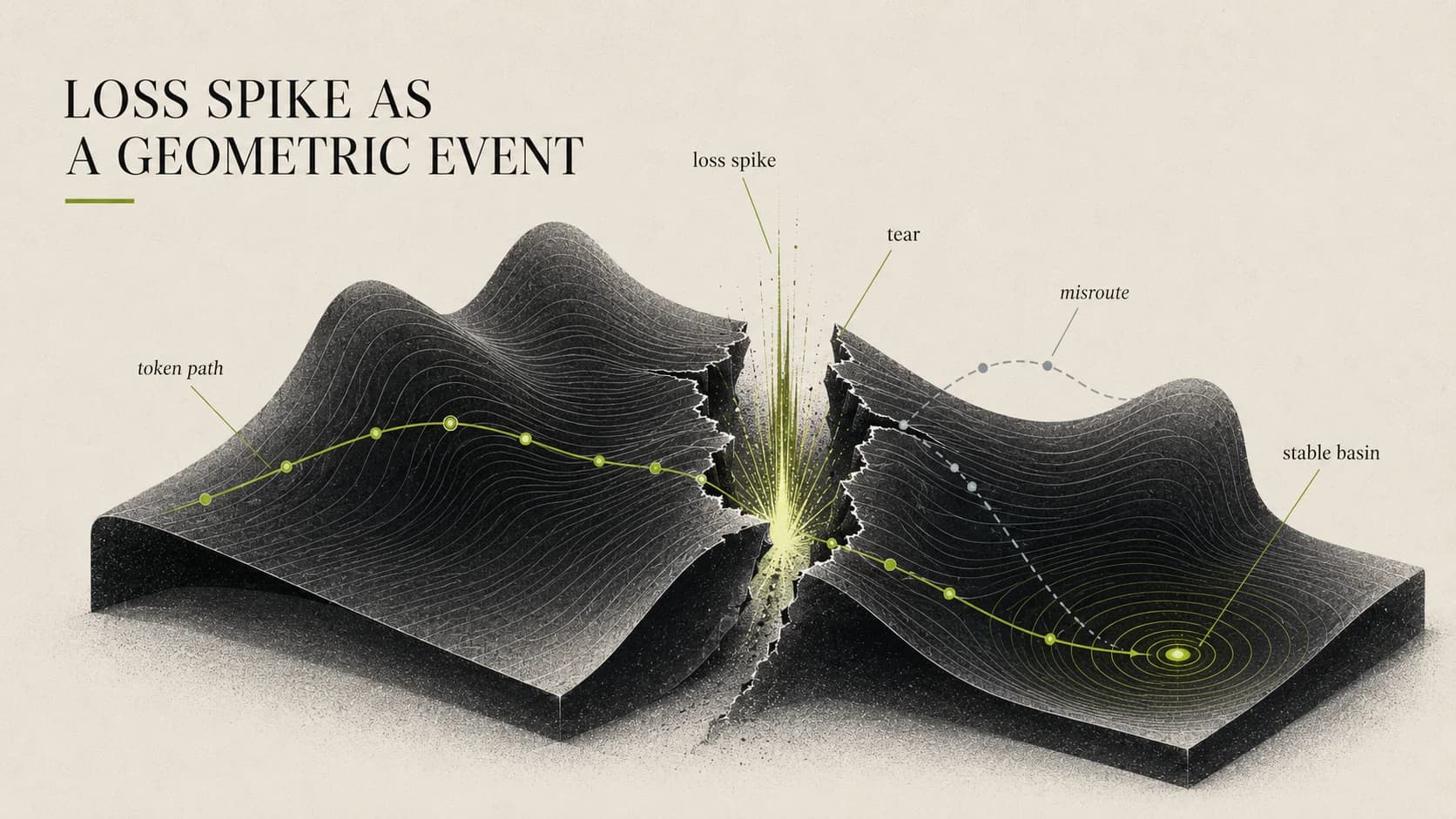
Note the words "discrete routing." This is exactly what MoE introduces. In a dense model, every token follows the same compute path, and there is no routing to speak of. In MoE, every layer's router makes a hard choice — and that hard choice is the entry point for "geometric inconsistency."
Tracing a single token forward, the failure decomposes into three stages.
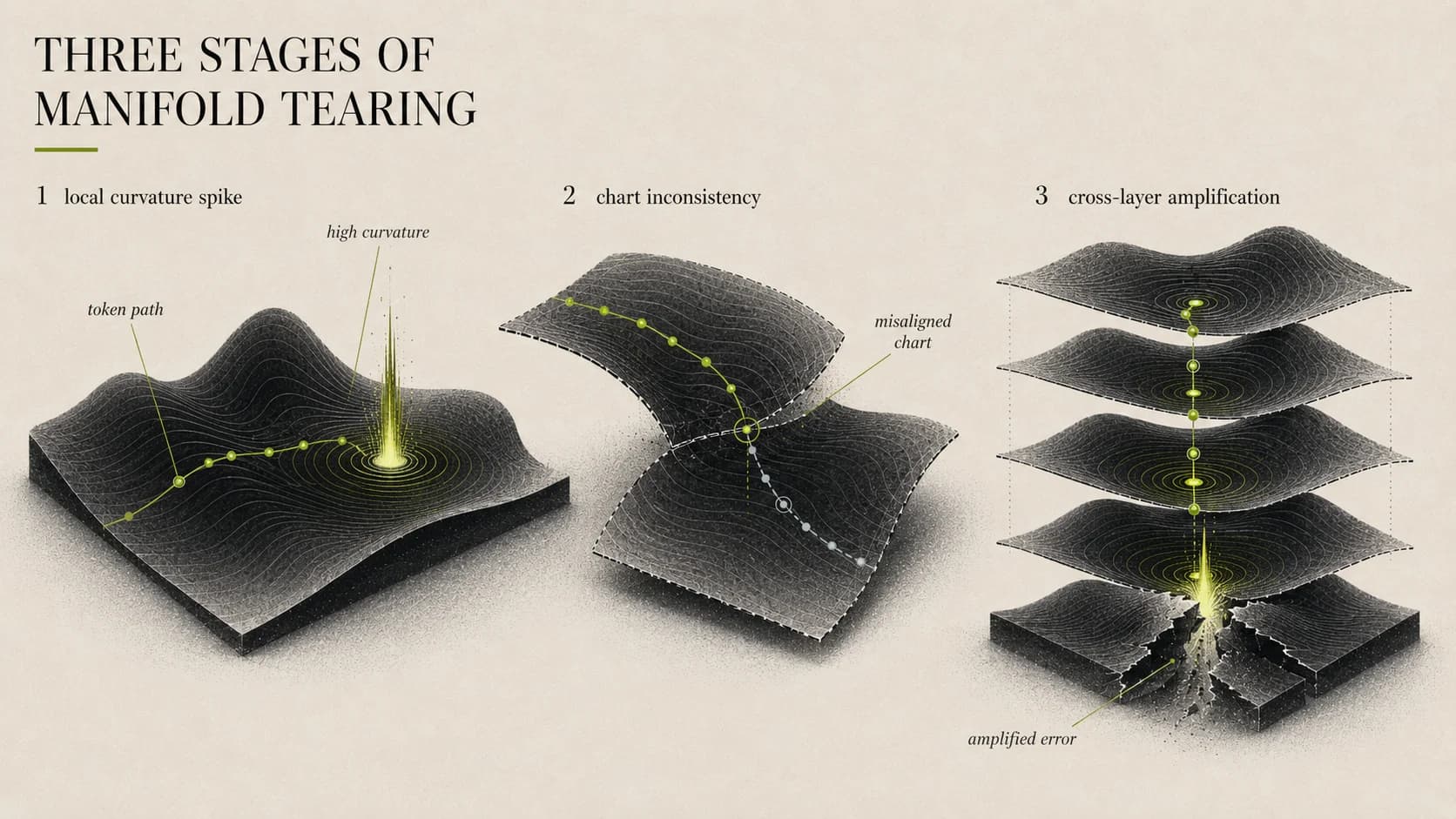
Stage 1: local curvature spike
Some activation regions develop high curvature; the second-order term stops being negligible. This is a very concrete mathematical issue: gradient descent implicitly relies on a first-order Taylor expansion
When the second derivative blows up, that approximation collapses. The hiking version: the slope flips from 30° to 85°, you take your normal step, and you've stepped into the air.
Stage 2: chart inconsistency
A manifold isn't described by one global map; it is a stack of local charts.
Model parameters update at every step, and here is the catch: the router uses parameters from one step ago, , while the token now lives on . The chart and the geometry no longer line up — you think you're somewhere on yesterday's map, but the terrain has shifted.
In MoE that means the router sends the token to the wrong expert. Not yet a full tear, but the start of instability.
Stage 3: cross-layer amplification
A misrouted token, processed by an expert that was never trained on this part of the manifold, produces an outlier output.
If the linear transformation matrix on the residual path has spectral norm > 1, that outlier compounds layer over layer. Stack a few dozen Transformer layers, and a tiny inconsistency at layer 5 can become a loss spike at layer 50.
In the video I keep saying: what kills iterative systems isn't a single big mistake — it is a small mistake every step. This is that.
3. DeepSeek V4's three geometric defenses
V4 doesn't try to eliminate any of these stages — that's not on the table. It puts a constraint on each, so the problem doesn't run away. The lookup table makes this clearest:
| Stage | V4 mechanism | Geometric meaning |
|---|---|---|
| Local curvature spike | SwiGLU Clamping | Keep activations inside the chart |
| Chart inconsistency | Anticipatory Routing | Parallel transport from the source geometry |
| Cross-layer amplification | mHC | Residual is a Lipschitz-1 map |
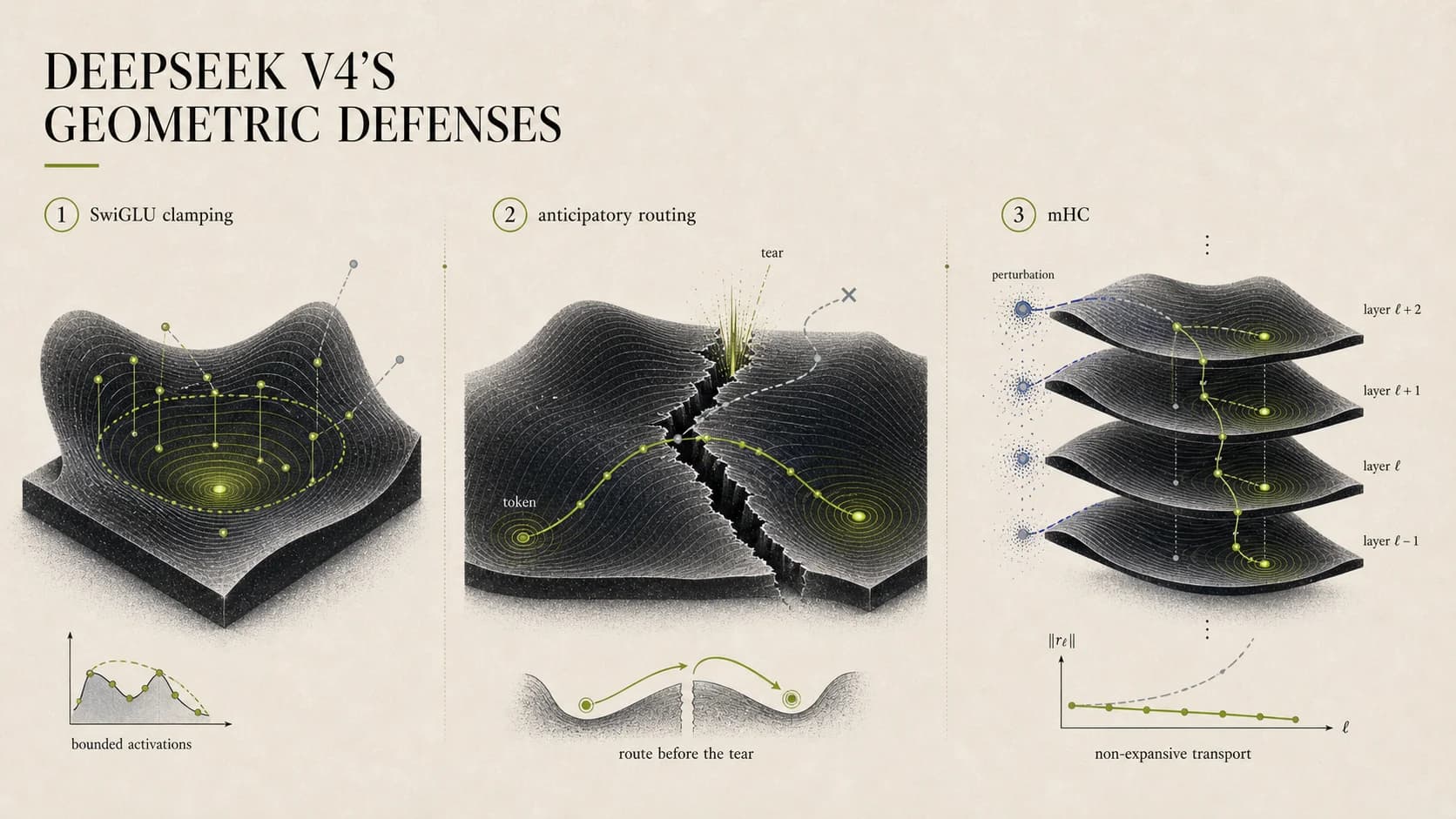
One at a time.
3.1 SwiGLU Clamping — bound the curvature inside the chart
SwiGLU has the form
V4's move is unsubtle: clamp to [-10, 10], and clamp the gate to ≤ 10.
It sounds like a hack; the geometric reading is sharp. Any chart is only valid inside its own local range; step outside and the first-order approximation collapses. Clamping is an explicit declaration of the chart boundary — activations are not allowed to leave.
In plain terms: forget about being on the optimal path. Just don't step off the edge of the map.
3.2 Anticipatory Routing — decide using the source geometry
V4 introduces a routing design that looks strange at first: the router doesn't use the current parameters ; it uses , parameters from a step ago.
Counterintuitive on first read — wouldn't yesterday's map be less accurate for today's data?
The geometric reading clears it up. Differential geometry has a core notion called a connection: when you transport a vector from one point to another, you need a self-consistent rule. A bad rule means going around a loop and finding your vector doesn't match the one you started with — that is curvature.
What Anticipatory Routing actually does: decide using the source-point geometry, not the destination-point geometry. It accepts a small loss in apparent accuracy in exchange for temporal consistency between charts. If the chart the router sees and the chart the token actually lives on disagree at the same instant, then have the router look at a more stable, slower-changing chart.
The neat part is V4 makes this reactive. Loss starts shaking, the mechanism kicks in — "treating geometric misalignment as a detectable, correctable event."
3.3 mHC — make the residual a non-expansive map
mHC (Manifold-Constrained Hyper-Connections) is described in the V4 report as "strengthening residual connections to improve cross-layer signal stability." Max Ma writes the math out and it gets clearer.
The hyper-connection update rule is
In a vanilla Transformer residual, , so the spectral norm equals 1. mHC makes learnable, but constrains it to the Birkhoff polytope — the set of doubly stochastic matrices:
Every row and every column sums to 1; all entries are non-negative. The constraint is enforced via Sinkhorn-Knopp iteration — alternating row and column normalization, converging to a point inside the Birkhoff polytope.
The geometric consequence is clean: doubly stochastic matrices have spectral norm ≤ 1, so
That is Lipschitz-1, also called a non-expansive map. Meaning: residual transport from layer to layer cannot amplify a perturbation. An upstream tear can at worst preserve its size; it cannot snowball.
The input/output mappings get a separate treatment: forced non-negative via sigmoid, to prevent "signal cancellation producing artificial zeros" — those zeros have no geometric meaning, they are numerical artifacts.
By now you can see the three defenses are co-designed:
- Clamping handles locality (don't leave the chart).
- Anticipatory Routing handles time (chart at and stay aligned).
- mHC handles space (tears don't stack across layers).
Drop any one, and the other two cannot carry the load.
4. Max Ma's deeper cut: the cause is in the data, not the architecture
If you stop here, this looks like a paper-walkthrough on V4's training stability. But the article slides in a much sharper claim:
Data — not architecture — is the primary cause. Training data with a discontinuous distributional structure induces a representation manifold that was never smooth to begin with.
That sentence does a lot of damage. It implies:
- mHC, Clamping, and Anticipatory Routing are all scaffolding, not the building.
- They prevent an already-fractured manifold from collapsing, but they did not create the fractures.
- The geometric quality ceiling is set by what you feed in.
Push it one step further. If your training data mixes samples from very distant distributions but treats them as semantically equivalent — code, natural language, math symbols, multimodal captions all in one stream — then V4's mechanisms keep training from crashing, but cannot guarantee the resulting manifold is good.
That is a harder problem than swapping architectures, and it is why I expect the next phase of competition to shift from "parameters + compute" to "data geometry."
5. Back to the Pointing-Mystery Realm: engineering evidence for the Four Realms
In The Four Realms of Neural Networks I placed training = manifold flattening at the second realm (指玄境, the Pointing-Mystery Realm), and cited Max Ma and Gen-Hua Shi's Deep Manifold framework — which formalizes this as "learnable numerical computation grounded in fixed-point theory."
That post also discussed the Muon optimizer: Newton–Schulz iteration projects each momentum update onto the nearest semi-orthogonal matrix, effectively writing "weights are geometric objects" into the optimizer.
DeepSeek V4 takes the same idea and pushes it into two new layers — forward propagation and MoE routing:
| Layer | What does it | Geometric move |
|---|---|---|
| Optimizer | Muon | Project updates onto the isometry group (semi-orthogonal) |
| Routing | Anticipatory Routing | Decide in the source-point geometry |
| Forward residual | mHC | Constrain residual map to the Birkhoff polytope (non-expansive) |
| Activation | SwiGLU Clamping | Bound curvature |
Four mechanisms, four positions, all doing the same kind of thing — explicitly admitting that weights and activations are geometric objects, and giving them update rules that respect that geometry.
This is the Pointing-Mystery Realm moving from "philosophical position" to "engineering default." When engineers reach for the Birkhoff polytope to constrain residual matrices, they are already thinking in geometric language — even if the paper doesn't quite say so.
Conclusion
A summary:
- Training a large model is an inverse problem — structure unknown, reverse-engineered from data. Inherently unstable.
- A loss spike is a geometric event — a topological tear, not an optimization blowup.
- V4's three defenses (Clamping / Anticipatory Routing / mHC) constrain along the curvature, time, and space axes, scaffolding a manifold that was never smooth.
- The real bottleneck is data — architecture-level stabilization is necessary, but it cannot smooth out a distribution that is intrinsically discontinuous.
- The direction is converging — Muon, mHC, and Anticipatory Routing all do the same kind of thing in different positions: treat the network as a geometric object, not a bag of parameters.
At the end of the video Max Ma uses the word elegant. A model that trains stably isn't built by stacking; it is the result of modules aligning with each other — like an orchestra in tempo. Every player can be excellent and the whole performance still be noise if the timing is off. What makes V4's design interesting is that it gives this alignment a geometric grounding, not just an empirical one.