A Geometric Diagnostic for Routing Discontinuity in Released Weights — Zhuo Zhang, Independent Researcher · 📄 阅读完整论文(PDF)→
这是 DeepSeek V4 与流形撕裂 的姊妹篇。那一篇是论点——loss spike 是几何撕裂,不是优化爆掉。这一篇是测量:我做了一个诊断工具,把它对准已发布的 MoE 权重,问一句:它到底被撕到什么程度。这篇博客是可读版;PDF 里有完整的方法、相关工作和可复现性附录。
在 DeepSeek 那篇里,我借了 Max Ma 和 Gen-Hua Shi 的 Deep Manifold 框架里的一个词:MoE 层不是在弯折表示,它会撕裂表示。弯折是连续的、无害的;撕裂是离散的,是病灶。故事讲得不错。但比喻是一笔债——总得有那么一刻,你要把撕裂亮出来,说清它有多大,再老实承认它会、和不会造成什么。
所以我把债还了。下面是一篇被压进博客的测量论文:一个几何诊断,跑在已发布的 OLMoE 和 Qwen 权重上,带负对照和 known-answer 自检。
一个欠了测量的比喻
一个 MoE 层把每个 token 路由到一小撮 top- 专家。这个离散选择让层间映射变成 不连续:两个任意接近、却落在路由边界两侧的隐藏态会被发往不同的专家——于是块输出可以跳变 。这个跳变就是撕裂。
已有工作从两个方向逼近它,却都没在真实模型上把它量出来:
- 连续化路由修法——ReMoE 明确把 top- 刻画成一次 jump discontinuity,并用 ReLU 路由替代它;Soft MoE、sparsemax/α-entmax 是它的亲戚。这些是把不连续消掉,而不是去量已发布权重里那一个。
- 路由翻转率——R3 router-replay 研究报告:训练引擎与推理引擎之间,约 10% 的 router、94% 的 token 至少翻转一个专家。那测的是专家集合多久变一次,不是这变化诱发的输出跳变。
没有人去测那个真正支配真实模型传输映射的量:已发布 LLM-MoE 权重上的输出跳变几何——跳变有多大、坐在哪、由哪个方向触发。这就是缺口。
撕裂到底是什么
一个 MoE 块把 映为
其中路由 logit 为 ,top- 取最大的若干个, 是在被选 logit 上重归一化的 softmax。把 logit 排序 , 活跃集边界就是
一个法向为 的超平面。越过它,你就换掉了第 个专家,块输出跳变 。这是一次货真价实的 不连续——对照一个 ReLU MLP,它是 连续的、只带 折角。
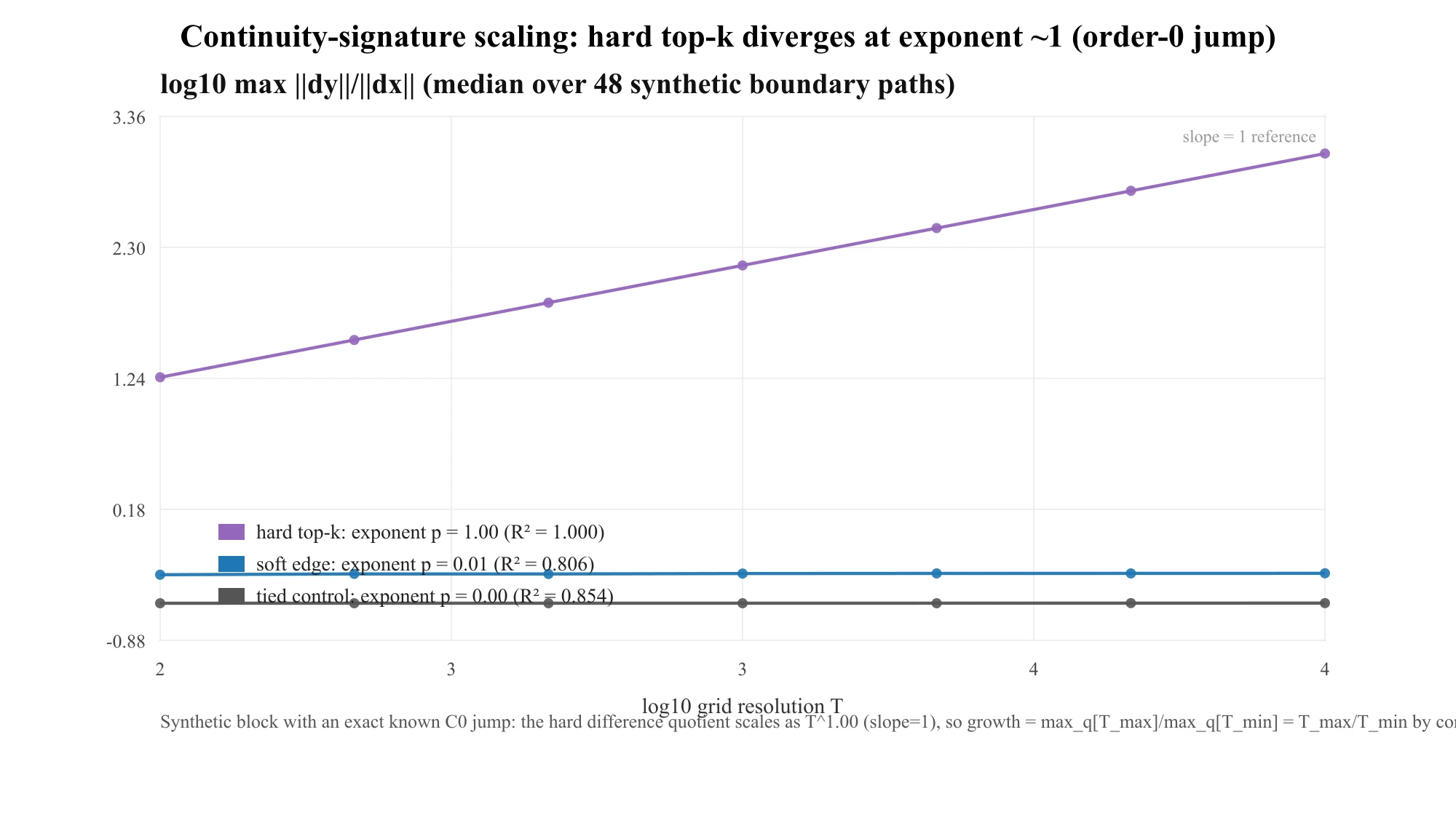
工具是一个差商:沿一条越界路径走,测 ,然后细化网格——我在分辨率 上采样。对连续映射,这个商会饱和;对一次货真价实的零阶跳变,它随分辨率线性增长,按 。判据是标度指数:跳变 ,连续映射 。
这里有个极易误读的点,我把话挑明。我把这个增长概括成 hardG =(分辨率 8000 处的最大商)/(分辨率 500 处的最大商)。对任意非零 跳变,这个比值——按构造——就只是网格比 ,与 、专家数、层都无关。所以 16× 不是严重度。 它是真零阶跳变在该协议下必然给出的值;它证认的是"奇点是零阶的、而且就在这",仅此而已。"更大"不等于"更糟"——根本没有"更大"。真正的严重度在别处:在每块输出跳变和专家悬崖上,都在下面。两个负对照让工具不撒谎——一个 tied-expert 对照(换专家是 no-op),一个连续性有保证的 soft-edge 门控——都必须停在指数 ()。
一个带精确已知 跳变的合成块把这条定律钉死:硬差商按 标度(拟合指数 1.0005,,分辨率 ),而对照保持平坦。这就是 known-answer 自检——它证认已发布权重上的 16× 是零阶跳变签名,而非探针假象,并解释了它为何跨层、跨模型、跨 都被钉住。
从中长出三个核心测量:
- M1 边界占比: margin 的分布,以及贴近边界的 token 比例。
- M2 专家悬崖: 归一化的 ,外加被换专家对的余弦。cos ≈ 1 是冗余(没有真撕裂);cos ≈ 0 是非冗余、停在 基线;cos < 0 才是真专精。这把"过度专精"和"仅仅非冗余"分开了。
- M3 连续性签名: 上面那个标度指数(跳变 ≈1、连续 ≈0),概括为 hardG,带它的两个对照。
所以严重度不在连续性签名里。它由每块跳变和 M2 承载——下文都请记住这个区分。
结果:已发布的 router 每一层都被撕开
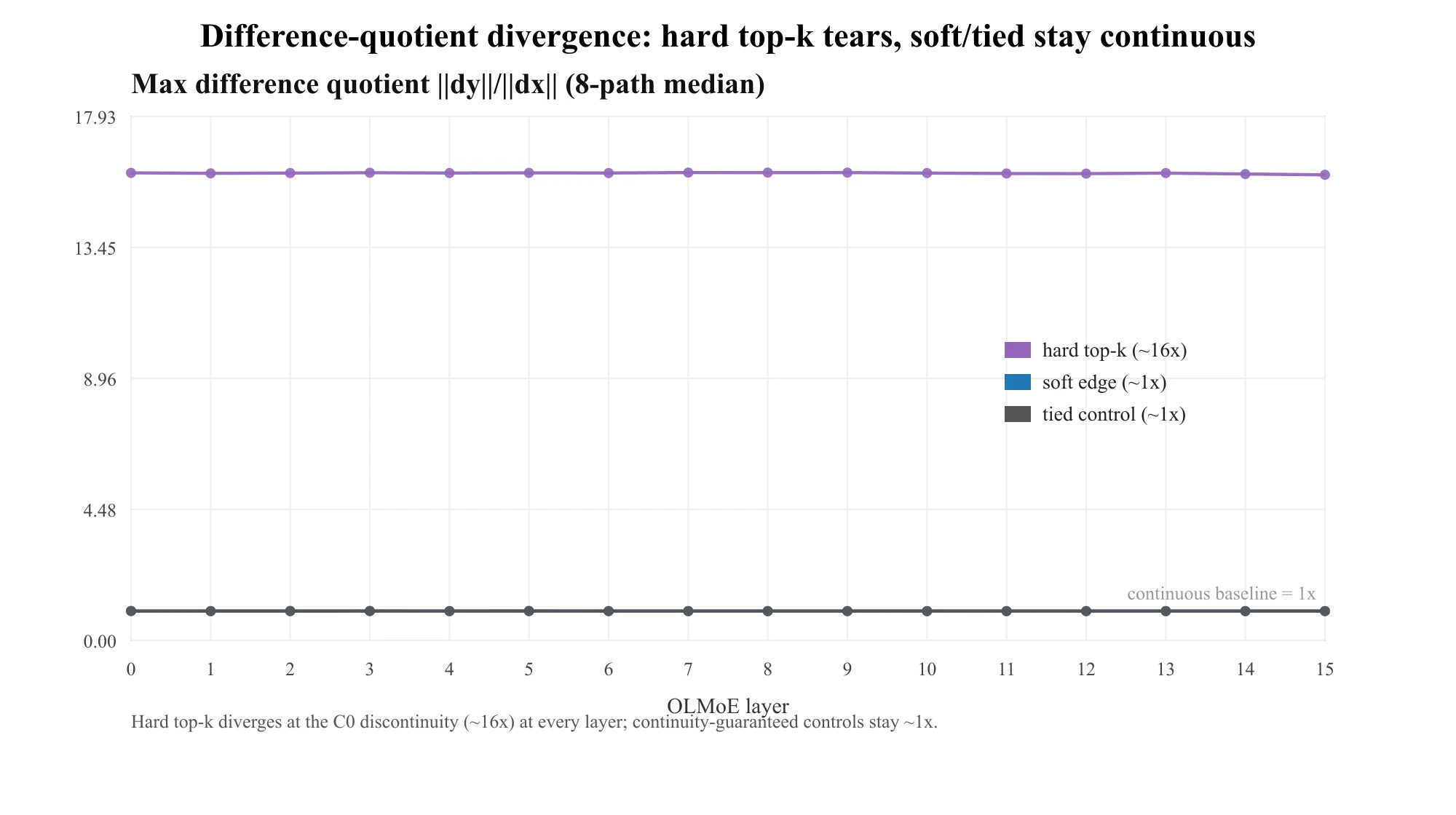
撕裂不是合成现象。在 OLMoE-1B-7B(16 层、64 专家、)上,连续性签名在每一层都是一次货真价实的零阶跳变——细化增长 hardG (标度指数 1.00,区间 15.93–16.01),差商按网格细化率发散——而两个对照都被钉在指数 ()。就是本文开头那张图。如上所述,这个 16× 是任意真跳变都会达到的网格比,不是严重度。严重度是另外两个数:每块输出跳变 ——约为块输出范数的 24%(一个每块几何量,不是模型输出、logits 或任务精度的变化)——以及专家悬崖 M2 、余弦 ,正好压在 无关向量基线上(非冗余、但并非过度专精)。靠近边界的比例 (margin 中位数 )。
表 1 — OLMoE-1B-7B 逐层诊断(24 条文本)。hardG 是细化增长(max@8000 / max@500);零阶跳变下它等于网格比 16,即指数 ≈1.00——其逐层近常数是协议的属性,不是模型的。块跳变列是每块输出跳变(占块输出范数的比例)。hardG、块跳变与两个对照是 8 条越界细化路径的中位数;margin、M2、cos 是层内逐 token 中位数。跨层来看:hardG 中位数 15.99×(指数 1.00)、M2 0.704、cos 0.025;块跳变均值 0.239;soft/tied 对照 ≈1.00。
| 层 | margin | M2 悬崖 | cos | hardG | 块跳变 | soft 对照 | tied 对照 |
|---|---|---|---|---|---|---|---|
| 0 | 0.0012 | 0.694 | 0.056 | 16.00 | 0.238 | 1.005 | 1.001 |
| 1 | 0.0009 | 0.701 | 0.033 | 15.98 | 0.309 | 1.003 | 1.002 |
| 2 | 0.0010 | 0.702 | 0.028 | 15.99 | 0.246 | 1.004 | 1.001 |
| 3 | 0.0011 | 0.704 | 0.022 | 16.00 | 0.248 | 1.004 | 1.002 |
| 4 | 0.0011 | 0.703 | 0.025 | 15.99 | 0.282 | 1.003 | 1.002 |
| 5 | 0.0012 | 0.702 | 0.030 | 16.00 | 0.288 | 1.004 | 1.002 |
| 6 | 0.0011 | 0.704 | 0.023 | 15.99 | 0.284 | 1.002 | 1.003 |
| 7 | 0.0014 | 0.704 | 0.026 | 16.01 | 0.233 | 1.003 | 1.002 |
| 8 | 0.0015 | 0.704 | 0.025 | 16.00 | 0.249 | 1.003 | 1.002 |
| 9 | 0.0019 | 0.703 | 0.026 | 16.01 | 0.266 | 1.003 | 1.002 |
| 10 | 0.0019 | 0.708 | 0.015 | 15.99 | 0.212 | 1.003 | 1.002 |
| 11 | 0.0021 | 0.709 | 0.012 | 15.98 | 0.244 | 1.003 | 1.002 |
| 12 | 0.0026 | 0.707 | 0.021 | 15.97 | 0.226 | 1.003 | 1.002 |
| 13 | 0.0023 | 0.709 | 0.015 | 15.99 | 0.157 | 1.003 | 1.002 |
| 14 | 0.0023 | 0.703 | 0.035 | 15.96 | 0.222 | 1.003 | 1.002 |
| 15 | 0.0028 | 0.600 | 0.301 | 15.93 | 0.123 | 1.003 | 1.002 |
第 15 层(末块)是唯一的轻微离群——悬崖更低(M2 0.60)、余弦更高(0.30 → 专家更冗余)——但它的不连续(hardG 15.93×)毫不减弱。
这不是 OLMoE 的怪癖。Qwen1.5-MoE-A2.7B(24 层、60 个路由专家、)复现了同一套模式:
| 指标 | OLMoE | Qwen1.5-MoE |
|---|---|---|
| hardG(连续性签名) | ≈16× 全层 | 15.99×(15.96–16.02) |
| M2 专家悬崖 | ≈0.70 | 0.710 |
| ≈0.025 | 0.010 | |
| 近边界比例(margin < 0.05) | ≈100% | 98.2% |
| 整块跳变 | ≈0.239 | 0.368 |
| tied / soft 对照 | ≈1.0× | 1.002× / 1.003× |
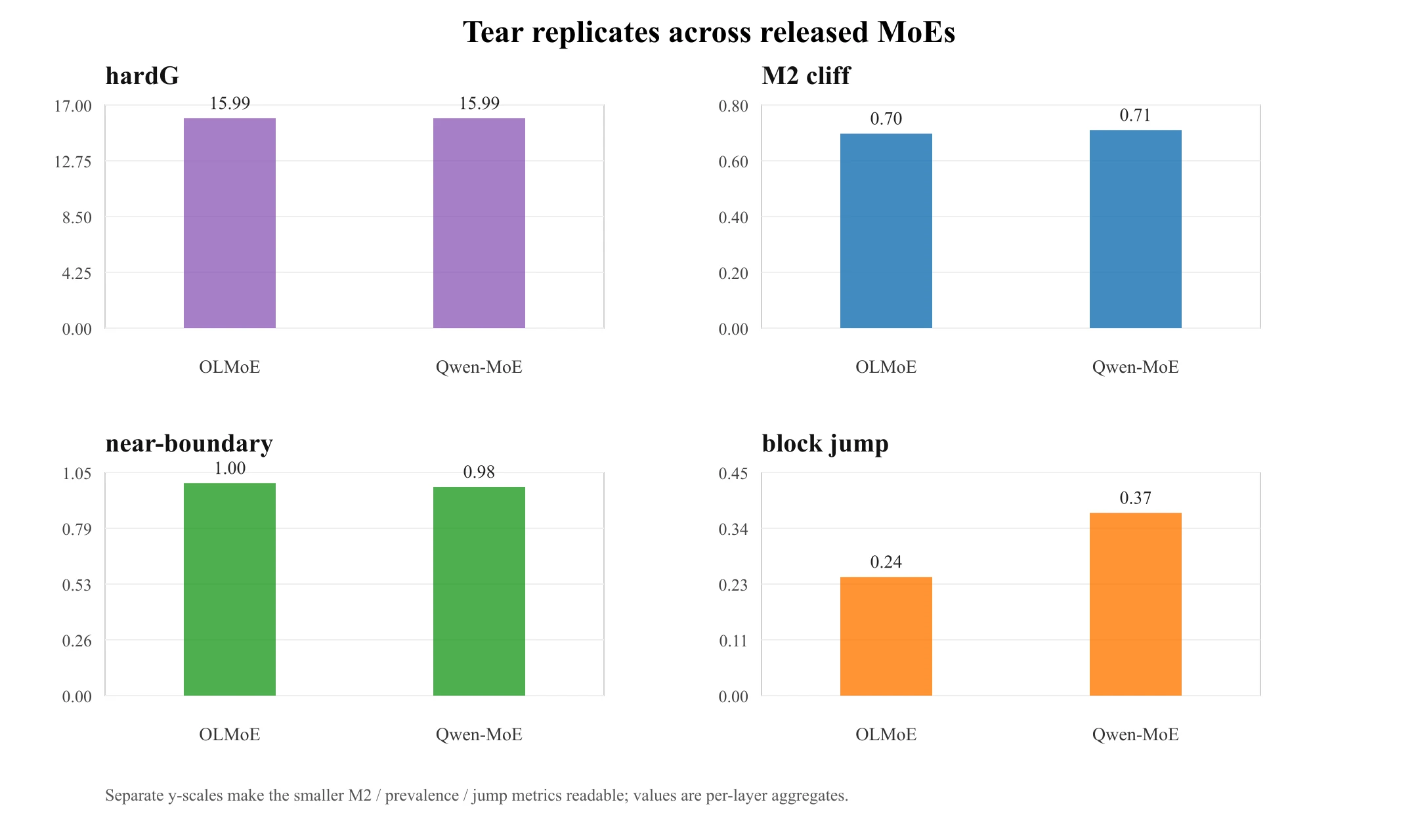
这个 16× 只是 的产物吗? 不是——而且不用再跑实验就有两条理由。(i) 按构造,细化增长对任意非零 跳变都等于网格比 8000/500,与 无关;从 到 16 没有任何代数路径。(ii) Qwen 路由 ,却落在与 OLMoE 的 相同的增长上(15.99×,指数 1.00)——若 16 是协议的网格比,这正是你预期的;若它由 决定,这就不该发生。(直接做 扫描可一锤定音;我把它留作未来加固。)
一句话总结:训练并不会把这道缝补上。 已发布的 router 在两个家族、每一层,都带着这个零阶不连续(指数 ≈1)——每块跳变实打实地约 24%,而悬崖 M2 ≈0.70 贴在无关向量基线上。
撕裂是方向性的——而这才是意外之处
直觉在这里栽了。最显然的鲁棒性测试是:随机扰动隐藏态,看消掉撕裂会不会让块更稳。答案是一个 null——而且这个 null 很有信息量。
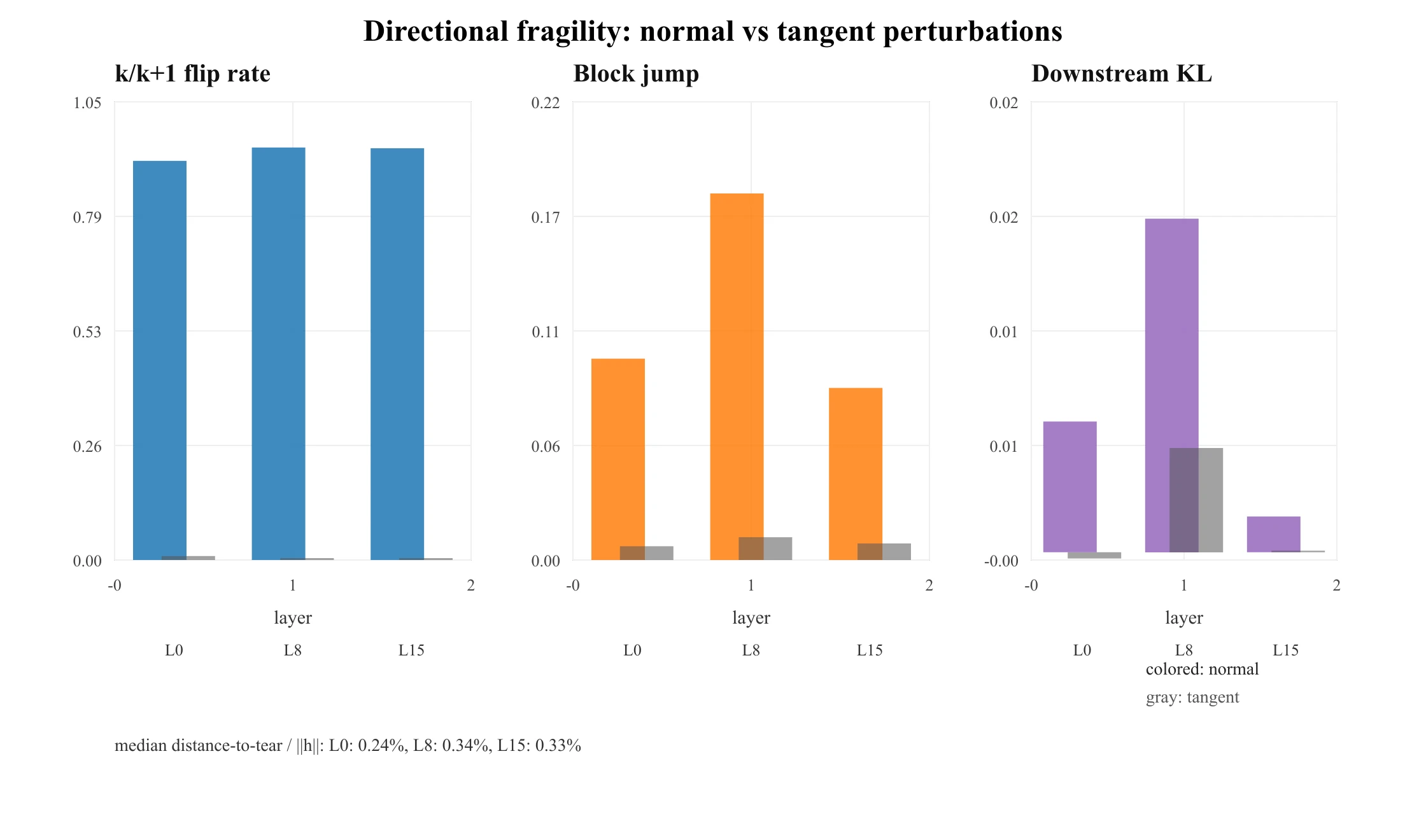
哪怕扰动大到翻掉 67.6% 的 token 的 top- 集合,硬-vs-软的块跳变也只差 2.6%(0.581 vs 0.566)。杀掉撕裂,几乎不改变块对随机噪声的响应。这个 null 不是说专家从不翻——这个幅度下 67.6% 的确翻了——而是说随机翻转在软门控本已产生的平滑响应之上,几乎不增加额外的不连续过量。
原因是几何的:随机扰动几乎总是切向于边界。 改成沿 raw-logit 边界法向扰动,取到撕裂距离的 ,画面就反过来了:
| OLMoE 层 | 法向翻转 | 切向翻转 | 法向跳变 | 切向跳变 | 法向 ΔKL | 切向 ΔKL |
|---|---|---|---|---|---|---|
| 0 | 0.915 | 0.009 | 0.098 | 0.0067 | 0.0063 | −0.0003 |
| 8 | 0.945 | 0.004 | 0.179 | 0.0111 | 0.0161 | 0.0050 |
| 15 | 0.944 | 0.004 | 0.084 | 0.0081 | 0.0017 | 0.0001 |
到撕裂的距离极小——中位数只有 的 0.24–0.34%——所以模型就住在边界上。一个不到 1% 相对幅度的法向轻推就翻掉专家( 概率),并产生 的每块输出跳变(占块输出范数的一部分,不是模型输出),带可测的下游 KL;而等幅度的随机/切向轻推几乎什么都不做。撕裂是可被利用的,但只沿一个特定的低维方向。
而且你没法廉价地把它重门控掉。连续化重门控能消除静态撕裂(softG ),但全层在推理期施加,会把困惑度从 10.04 抬到 159.94(15.9×)——还是最温和阈值下的数。单层重门控则温和得多()。所以任何实用缓解要么针对特定层,要么像 DeepSeek-V4 那样并进训练,而不是事后外挂。
训练期:它被分解,而非被引爆
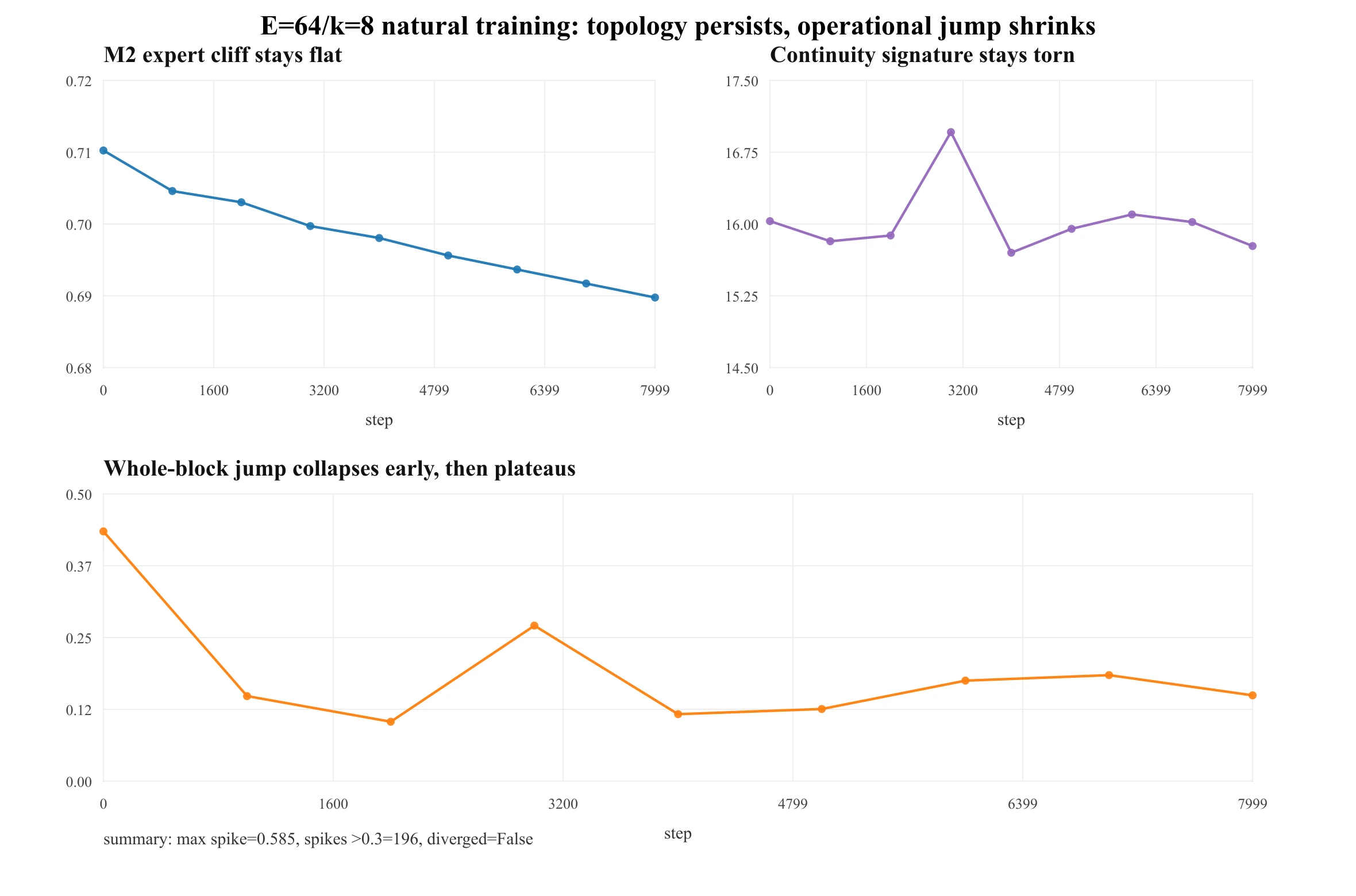
这是诚实的负面结果,也是让比喻不至于过界的那一段。为了探训练,我用了一个受控的从零开始的 GPT-MoE 探针,几何对齐到 OLMoE-近似量级(E=64、k=8、约 308M 参数)——不是那个 7B 模型的预训练。
机制(真实、但不大): 参数空间的差商探针发现硬路由比连续性匹配的软门控更粗糙——2.0× vs 1.4×。方向上与合成的 4.5× 一致,但随着几何变现实而变弱。
结果: 自然训练是多尖峰但收敛的,而撕裂不会自愈。8000 步里有 196 个 >0.3 的尖峰(最大 0.585),却没有发散(终损 3.27)。M2 维持 0.711 → 0.690、hardG 全程 ,而操作性的整块跳变早期就塌(0.431 → ≈0.15),随后进入一条噪声带。训练压住的是撕裂的后果,不是它的拓扑。
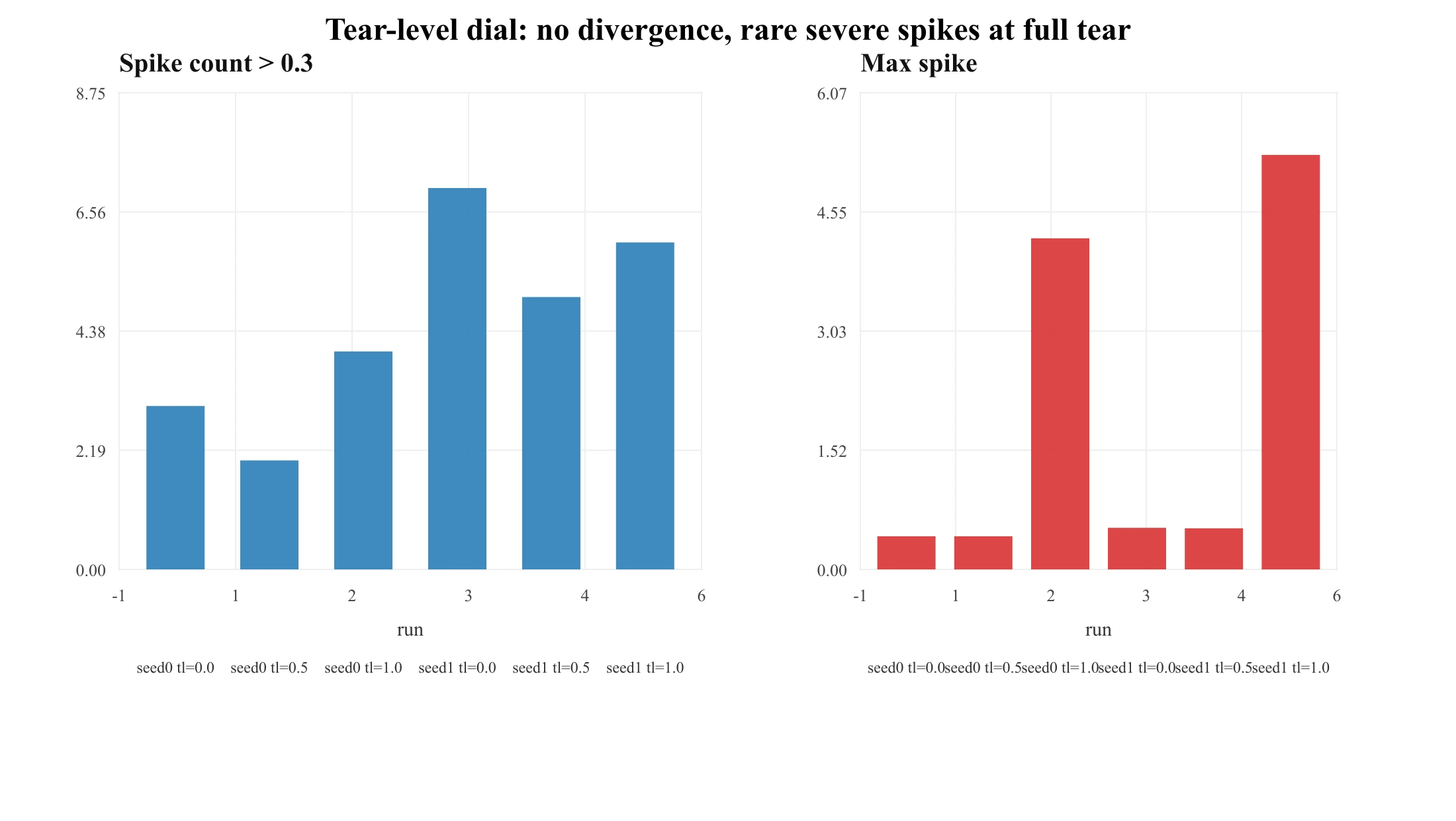
再往边界推一把,用一个跨两个种子、贴在稳定边缘的撕裂幅度旋钮:
| 种子 | tear_level | >0.3 尖峰数 | 最大尖峰 | 是否发散 |
|---|---|---|---|---|
| 0 | 0.0 / 0.5 / 1.0 | 3 / 2 / 4 | 0.42 / 0.42 / 4.21 | 否 / 否 / 否 |
| 1 | 0.0 / 0.5 / 1.0 | 7 / 5 / 6 | 0.53 / 0.52 / 5.28 | 否 / 否 / 否 |
没有一次运行发散。 尖峰数甚至不随撕裂幅度单调。但满撕裂会可复现地催生一个罕见的严重但可恢复尖峰(最大 ≈4–5 vs ≈0.5)。诚实的说法:撕裂带来优化粗糙度和罕见的尖峰严重度,但在这个尺度上,单凭它不足以导致崩溃——动量和 Adam 把它吸收了。尺度依赖性仍未解决,而那恰恰是 DeepSeek-V4 的工程开始相关的地方。
用几何读 DeepSeek-V4 的三道防线
这里就接回了 DeepSeek 那篇。关键的提醒是:路由不连续 ≠ loss spike。 不连续只是若干可分因子里的第一个:
- 路由不连续——方向性的,几何入口(上文)。
- 专家离群幅度——跳变随它放大;我测得 与 换专家跳变的相关 +0.437(高范数 token 跳得更多)。
- 时序 backbone/router 失配——本文未测(未来工作)。
- 跨层传播增益——下游 KL / 注入跳变 (一个非膨胀残差给它封了顶)。
- 优化器吸收——上面那个训练结果。
DeepSeek-V4 的三道干预干净地落在因子 2–4 上——它们控制的是后果,不是拓扑:SwiGLU clamping(因子 2)、Anticipatory Routing(因子 3)、流形约束的 hyper-connections(因子 4——一个在 Birkhoff polytope 上的残差映射,谱范数 ≤ 1,非膨胀)。
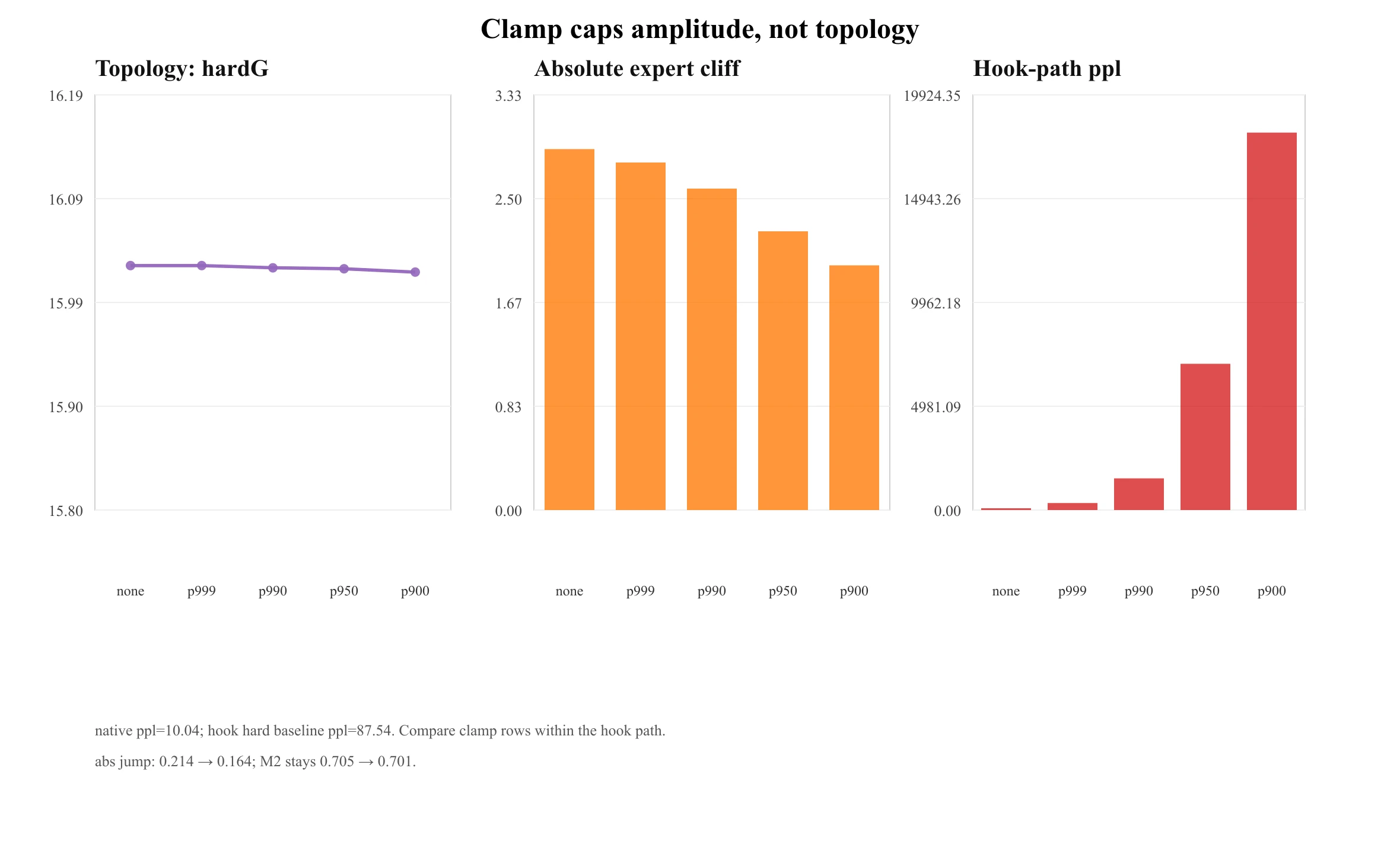
第一个我可以直接验。一个 SwiGLU-clamp 扫描跑在已发布 OLMoE 上,拓扑保持平坦——hardG 16.03 → 16.02、M2 0.705 → 0.701——同时压低绝对幅度(专家悬崖 2.90 → 1.97、绝对 hardJump 0.214 → 0.164);相对跳变保持尺度不变(0.310 → 0.303)。clamp 压的是跳变的幅度,不是它的存在——这是把 DeepSeek 的分解量出来,而不是断言出来。
在 DeepSeek 那篇里我画过这张表,论点是 V4 的四个机制在不同位置做着同一种事——承认权重和激活是几何对象:
| 位置 | 机制 | 几何动作 |
|---|---|---|
| 优化器 | Muon | 把更新投影到等距群 |
| 路由 | Anticipatory Routing | 在源点几何里做决定 |
| 前向残差 | mHC | 把残差约束到 Birkhoff polytope(非膨胀) |
| 激活 | SwiGLU clamping | 给曲率封顶 |
这里的测量说:那些机制所尊重的几何是真切在那儿的——在已发布的权重里,每一层都是一次货真价实的零阶不连续——无论优化器在训练时有没有恰好撞上它。
它是什么,不是什么
这是一个测量/分析结果,我想把它的边界说清楚:
- 它不提出新门控、不提出新的 分类法、也不声称首次发现这个不连续。那些归 ReMoE、Puigcerver 等人(2022)和样条理论那条线所有。
- 它增加的是:一个能跑在已发布权重上、带负对照和 known-answer 自检的诊断;一个跨模型刻画(OLMoE + Qwen);一个方向性的推理结果外加缓解上界;以及一个诚实的训练期分解,拒绝过度声张。
底线:MoE 路由撕裂是真实、可测、跨模型的——一次货真价实的 跳变(差商在每一层都按标度指数 ≈1 发散,对照平在 ≈0),被训练后的路由器一直携带而非缝合。它在每块输出跳变上是严重的(约为块输出范数的 24%)——不在诊断的 16×(那是网格比,不是幅度),也不在专家专精上(M2 贴在无关向量基线上)。它的推理后果是方向性的:随机输入错过它,不到 1% 幅度的边界法向输入命中它,而你没法事后免费把它重门控掉。它的训练期角色是一个分解,而非单一成因——这恰恰是为什么工程手段压的是幅度,而不是移除撕裂。
DeepSeek 那篇说,把网络当几何对象正从哲学立场变成工程默认。这一篇,补上了那个立场一直缺的数字。
几句直说的注意。连续性签名证认的是奇点的阶(指数 ≈1 vs 对照 ≈0)及其位置——它不测严重度;其 16× 增长是任意真跳变都必然给出的网格比,不是模型属性,也不是"越大越糟"。这里每个数都是隐藏态上的几何量:约 24% 的块跳变和边界法向脆弱性并不绑定端到端任务精度(GSM8K、MMLU),而且跳变是逐层测的,撕裂如何跨叠层传播、复合则未测。此外:两个模型家族、24 条短文本;一个小规模 308M 训练探针(尖峰严重度信号可能依赖尺度);hardJump 轨迹每步只用一条路径(多路径重采样才能给误差棒);clamp 质量在 hook 路径内部测;时序失配因子点了名但未测。Deep Manifold(Ma & Shi)仅作动机引用——它是外部既有工作,不是我自己的框架。数字的真值来源是一组 result JSON;每张图都用一个仅依赖标准库的 SVG 脚本从中重新生成。
参考文献
完整的方法与可复现性附录在论文 PDF 里。
- Ziteng Wang, Jun Zhu, Jianfei Chen. ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing. ICLR 2025. arXiv:2412.14711
- Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby. From Sparse to Soft Mixtures of Experts. ICLR 2024. arXiv:2308.00951
- André F. T. Martins, Ramón Fernandez Astudillo. From Softmax to Sparsemax. ICML 2016. arXiv:1602.02068
- Ben Peters, Vlad Niculae, André F. T. Martins. Sparse Sequence-to-Sequence Models. ACL 2019. arXiv:1905.05702
- Joan Puigcerver, Rodolphe Jenatton, Carlos Riquelme, Pranjal Awasthi, Srinadh Bhojanapalli. On the Adversarial Robustness of Mixture of Experts. NeurIPS 2022. arXiv:2210.10253
- Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, Fuli Luo. Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers (R3). 2025. arXiv:2510.11370
- Boris Hanin, David Rolnick. Complexity of Linear Regions in Deep Networks. ICML 2019. arXiv:1901.09021
- Randall Balestriero, Richard Baraniuk. A Spline Theory of Deep Networks. ICML 2018. arXiv:1805.06576
- Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, Yoshua Bengio. On the Number of Linear Regions of Deep Neural Networks. NeurIPS 2014. arXiv:1402.1869
- William Fedus, Barret Zoph, Noam Shazeer. Switch Transformers. JMLR 2022. arXiv:2101.03961
- Barret Zoph et al. ST-MoE: Designing Stable and Transferable Sparse Expert Models. 2022. arXiv:2202.08906
- Dmitry Lepikhin et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. ICLR 2021. arXiv:2006.16668
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. 2026. arXiv:2606.19348
- Max Y. Ma, Gen-Hua Shi. Deep Manifold Part 1: Anatomy of Neural Network Manifold. 2024. arXiv:2409.17592
- Max Y. Ma, Gen-Hua Shi. Deep Manifold Part 2: Neural Network Mathematics. 2025. arXiv:2512.06563
- Niklas Muennighoff et al. OLMoE: Open Mixture-of-Experts Language Models. 2024. arXiv:2409.02060
- Qwen Team. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters. 2024. Model blog
延伸阅读:DeepSeek V4 与流形撕裂 · 神经网络的四重境界