
The most expensive line in modern AI training is not the matrix multiply. It is the activation buffer.
End-to-end backpropagation requires holding the activations of every layer alive until the backward pass arrives. For a 24-layer transformer, that means 24 snapshots of the residual stream sitting in GPU memory at once. Scale depth, and you scale the memory bill in lockstep. This is why the 100B-parameter training runs need hundreds of A100s, and why most researchers have never trained anything remotely that large.
Sakana AI's DiffusionBlocks (ICLR 2026) dissolves this constraint. The framework is validated across five architecture families — ViT, DiT, autoregressive, recurrent-depth, and masked diffusion — and the headline result is blunt: block-wise training matches end-to-end performance while cutting peak training memory by roughly the block count. Their paper is clear and worth reading on its own terms. But the question it does not fully answer surfaces in the block-count ablation: why does a small B — and B=3 in particular — work so consistently?
I think the answer is already in the residual stream data, and it connects directly to the manifold view of what neural networks are doing.
What DiffusionBlocks Actually Does
The paper's core insight is that residual connections are not just a skip-gradient trick. They are Euler discretization steps of the probability flow ODE:
Each residual block update z_l = z_{l-1} + f(z_{l-1}) is one Euler step along this trajectory — one denoising step in the reverse diffusion process. The network, already structured this way, can be partitioned into B blocks, each assigned a contiguous noise level range [σ_high, σ_low]. Each block then learns the score function (the denoising direction) for its assigned range via score matching loss, completely independently of the other blocks.
For a 12-layer ViT with B=3, the paper's experimental setup (Section 5.1) is exactly this: three blocks of four layers each, each trained on its own σ range, assembled in sequence at inference. Memory drops to 4 active layers at any training moment instead of 12.
Crucially: no learned connector module is inserted between blocks. The block decomposition governs how the training signal is computed, not the model's architecture. A discriminatively-trained model (the ViT classifier) runs the same forward pass it always did; a generative model runs the usual diffusion sampling loop — one ODE-solver step per noise level, each routed to the block that owns that σ range. Either way, the blocks are stitched together by machinery that already existed, not by anything the method bolts on.
The Block Count Problem
The paper's ablation on DiT shows something worth pausing on:
| B | FID (↓) | Memory reduction |
|---|---|---|
| B=1 (end-to-end) | 12.09 | 1× |
| B=2 | 9.90 | 2× |
| B=3 | 11.11 | 3× |
| B=4 | 11.90 | 4× |
| B=6 | 14.43 | 6× |
B=2 and B=3 both beat the end-to-end baseline on FID. B=4 and B=6 start degrading. The paper explains this through diffusion theory: equi-probability partitioning of the noise range works best when each block gets a learning task that is balanced in difficulty. Too few blocks and you waste the independence property. Too many blocks and each block's assigned σ range is too narrow to learn anything globally coherent.
That's the theoretical explanation. But there is a structural one underneath it.
The Empirical Case: The Network Was Already Trifurcated
Earlier this year I ran a layer sweep on a 32-layer Llama 3.1 transformer, measuring the residual stream's correlation (r) at representative layers (notebook here):
Layer 1: r = 0.5091
Layer 4: r = 0.3478 ← minimum: maximum active reshaping
Layer 8: r = 0.3827
Layer 12: r = 0.4139
Layer 16: r = 0.6489 ← step change: manifold consolidating
Layer 20: r = 0.6782
Layer 24: r = 0.7279
Layer 28: r = 0.8540 ← plateau: stable task representations
Layer 30: r = 0.8112
Layer 32: r = 0.8250Read this in the 指玄境 frame — the Pointing-Mystery Realm, where training is the geometric flattening of a manifold. The r here measures behavioral isometry: at a given layer, how faithfully the geometry of concepts in the residual stream mirrors the geometry of the model's output behavior. Low r means the activation geometry does not yet track behavior — the manifold is still being actively deformed into shape. High r means the two are aligned — the manifold has been found, and subsequent layers refine on a fixed geometric base.
Three phases are visible without squinting:
Phase 1 (layers 1–~10): Embedding flattening. Low, dipping r. The token embeddings arrive tangled — France, 法国, and the concept of a European nation all need to end up pointing at the same geometric region. These layers are actively rotating, stretching, and cutting the ambient space, doing the topological work of manifold separation. The r dips to 0.34 at layer 4 — the point of lowest behavioral isometry, where the activation geometry least resembles the output structure it will eventually encode.
Phase 2 (layers ~10–22): Geometric manifold construction. The rising r from ~0.41 to ~0.67. The manifolds have been roughly separated; now they need to be shaped into the smooth, linearly-separable surfaces that make downstream classification or generation tractable. This is where the network develops what Olah's manifold topology work calls the "clean geometric structure" — the curved surfaces become progressively flatter, and the Muon-optimal geometry begins to solidify.
Phase 3 (layers ~22–32): Task following and generalization. r stabilizes above 0.75 and climbs to 0.85. The manifold is essentially found. These layers are not restructuring geometry — they are applying task-specific transformations to a stable geometric substrate. The residual stream is drifting toward final answer space rather than reorganizing.
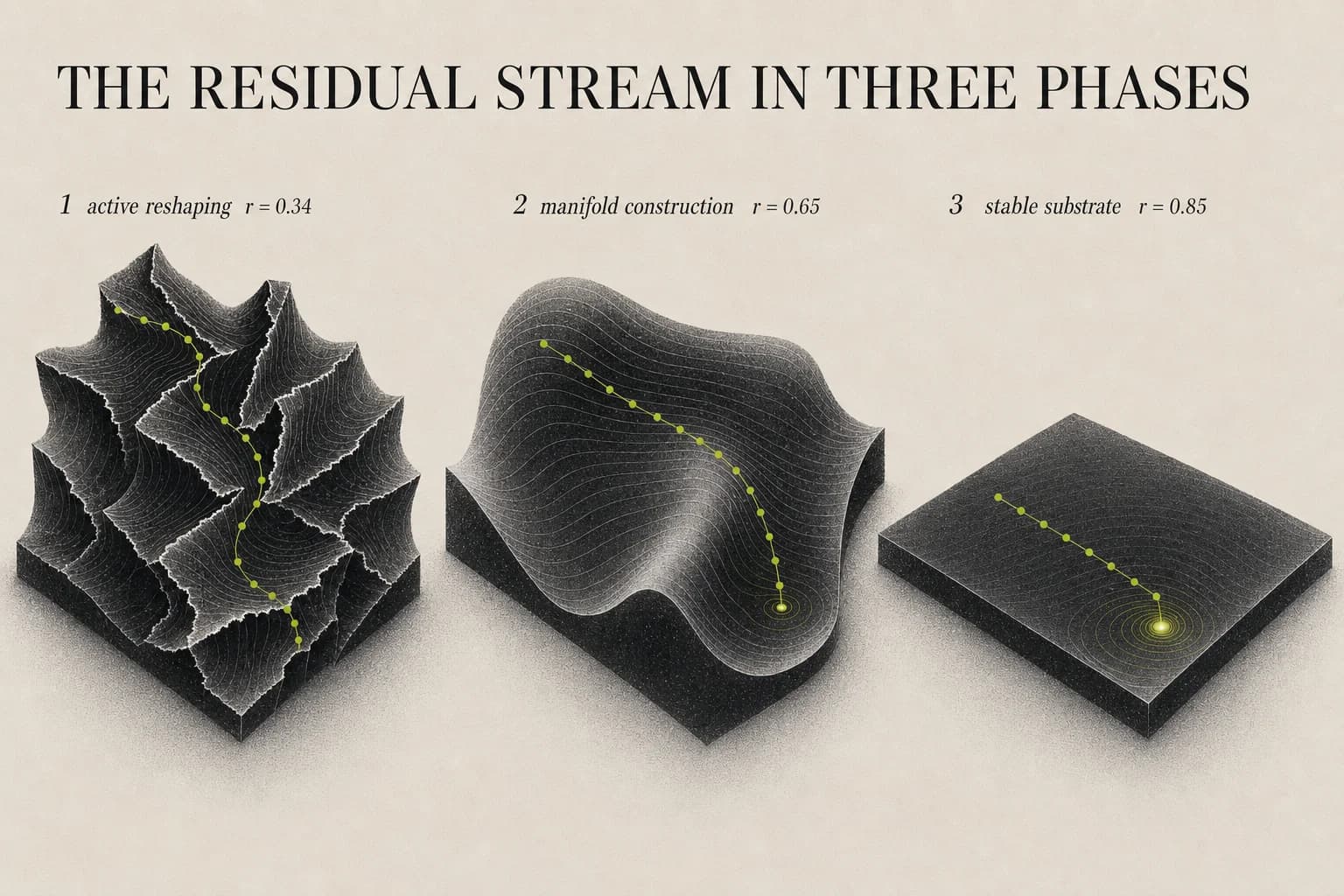
This is not a post-hoc interpretation — it is what the correlation structure of the residual stream looks like before you know about DiffusionBlocks. The network has independently discovered a natural trifurcation.
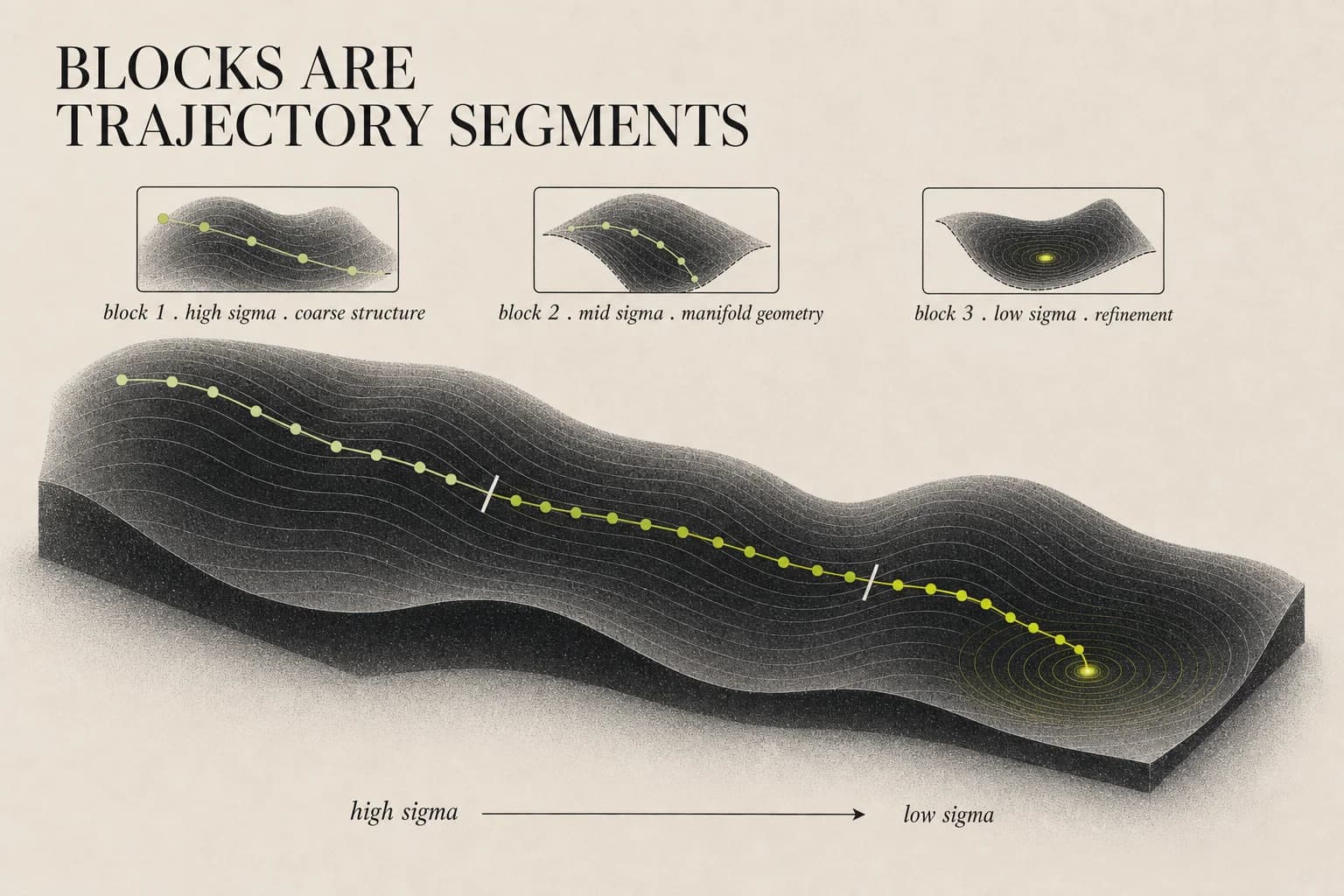
One caveat: the sweep above is a 32-layer decoder LLM, while DiffusionBlocks is validated on ViT, DiT, and others — so I'm treating the three-phase structure as a general property of deep residual stacks rather than something proven architecture-by-architecture. With that said: when DiffusionBlocks assigns B=3 blocks to a 12-layer model, it is partitioning a structure that already exists functionally. Block 1 handles the high-σ range where coarse structure forms — this is the embedding-flattening phase. Block 2 handles mid-σ — manifold geometry. Block 3 handles low-σ — task refinement. The equi-probability partition the paper proposes — equal probability mass per block, which need not land on equal layer boundaries — falls, not by design, near the natural phase structure of the residual stream.
This is why quality holds through B=3 and then erodes: B=4 slips behind B=2/B=3 (though it still edges the end-to-end baseline), and by B=6 it drops below baseline entirely. The network has three structural phases; cutting at two or three boundaries lands at or inside the natural seams, while cutting finer divides a single phase across blocks that each see too little of it to learn a coherent denoising task. The functional structure resists being cut finer than it is.
It also explains the number a naive "three is the magic number" reading would trip on: B=2 (9.90) actually edges out B=3 (11.11) on FID. The phases aren't hard walls — they're soft regimes. The Phase-2→Phase-3 transition in the r-curve is a smooth ramp (0.41 → 0.67 → 0.85), so a three-way cut has to place one boundary inside that ramp, while a two-way cut — active reshaping vs. everything after — splits difficulty more cleanly. So the trifurcation sets the ceiling on useful blocks, not a single optimum. B=3 is the sweet spot for training specifically: it buys 3× memory at near-best quality, and the structural ceiling is what makes paying so little for it safe.
The ODE Connection
The Diamond Realm (金刚境) of the 四境 (Four Realms) framework already made this claim: forward propagation is Euler integration of an ODE. DiffusionBlocks formalizes exactly this at the training level. The residual connection is not just "ODE-like" in a loose sense — it is a specific Euler discretization of the probability flow ODE from score-based diffusion theory, equation (1) in the paper. The dynamical system perspective was always implicit; DiffusionBlocks makes it load-bearing.
The practical consequence: you can now train the ODE one trajectory segment at a time. Blocks are trajectory segments. The three segments correspond to the three geometric phases. This is what makes the independence property work — each segment of the ODE trajectory has its own local score function, which can be learned without global information about the rest of the trajectory.
What This Changes (and What It Doesn't)
What it changes: memory scaling during training. This is genuine and important. A well-tuned B=3 partition means you only need the memory budget for 1/3 of the network at any time. For practitioners training large models on constrained hardware, this is not a minor win.
What it doesn't change: the fundamental geometry of what the network is learning. What the paper actually demonstrates is performance parity — a DiffusionBlocks-trained ViT matches the end-to-end model, and at B=2–3 beats it on FID. It does not measure the learned geometry directly. But the manifold view tells you why parity should hold: the training path is different; the destination is the same fixed point on the manifold space. Same geometry, reached two ways — that is my reading, and the parity numbers are exactly the footprint it would leave.
This is what the manifold view predicts: if many valid paths lead to the same well-flattened manifold geometry, then any principled local objective that navigates each path segment correctly will converge there. DiffusionBlocks gives each block a principled local objective (score matching on its σ range) rather than an ad-hoc auxiliary loss — which is why it works where earlier block-wise methods (Forward-Forward, greedy layer-wise training) struggled.
The Broader Pattern
DiffusionBlocks joins a growing list of papers that are, from the manifold view, rediscovering the same structural truth through different experimental lenses:
- DeepSeek V4's loss spike defenses (manifold tearing post) — three independent engineering solutions to what is geometrically the same problem: sudden deformation of the residual stream manifold
- Muon optimizer — orthogonal weight updates preserve the geometric structure the manifold view says matters; empirically wins on NanoGPT speedruns
- DiffusionBlocks — local training objectives aligned to the ODE trajectory's natural phase structure work because the functional decomposition is real, not imposed
The pattern is: every time someone finds a principled local objective that respects the natural phase structure of the residual stream, it works as well as global backpropagation and often better. The network has always wanted to be three parts. It is taking us a while to notice.
The DiffusionBlocks paper: arxiv.org/abs/2506.14202
Layer sweep notebook: github.com/waylandzhang/manifold-steering-demo-n-critique
Four Realms framework: waylandz.com/blog/four-realms-of-neural-networks