在上一篇关于 AI 量化交易的文章里,我梳理了这个领域的全貌:量化交易到底是什么,为什么 AI 确实有优势,以及真正的门槛在哪里。结论很清楚:量化基金的神秘感不来自智力复杂度,而来自信息不对称和工程执行。
这篇是后续。过去几个月,我们一直在构建 Dnalyaw——一个垂直整合的量化交易平台,让研究和执行从头到尾共享同一条 pipeline。核心 thesis 很简单:在现代市场里,护城河不是某一个模型或信号,而是拥有从想法到实盘资金的完整闭环;中间有数百个特征、几十个系统化策略,以及严格的风险控制。
这篇文章会讲架构、背后的工程决策,以及为什么真正会复利的优势来自垂直整合,而不是模型新奇度。
为什么从零开始构建?
诚实答案是:现有框架不尊重延迟层级。
大多数开源量化平台把一切都当成同一类问题处理——从上到下都是 Python。这对研究没问题。但当你需要在每一笔订单上做亚微秒级风险检查,同时还要跑 ML inference、管理跨全球市场的数百个持仓时,它会失败得非常壮观。
另一个问题是风险。当真实资金在场时,你不能接受“尽力而为”的风控作为一层后贴的 middleware。风险引擎必须拥有否决权。它必须在物理架构上不可能被 rogue strategy 或行为异常的 LLM agent 绕过。这需要架构隔离,而不只是一个 Python decorator。
多语言架构:Rust + Go + Python
Dnalyaw 使用三种语言,每一种都对应一个特定延迟层。这不是为了复杂而复杂,而是让工具匹配约束。
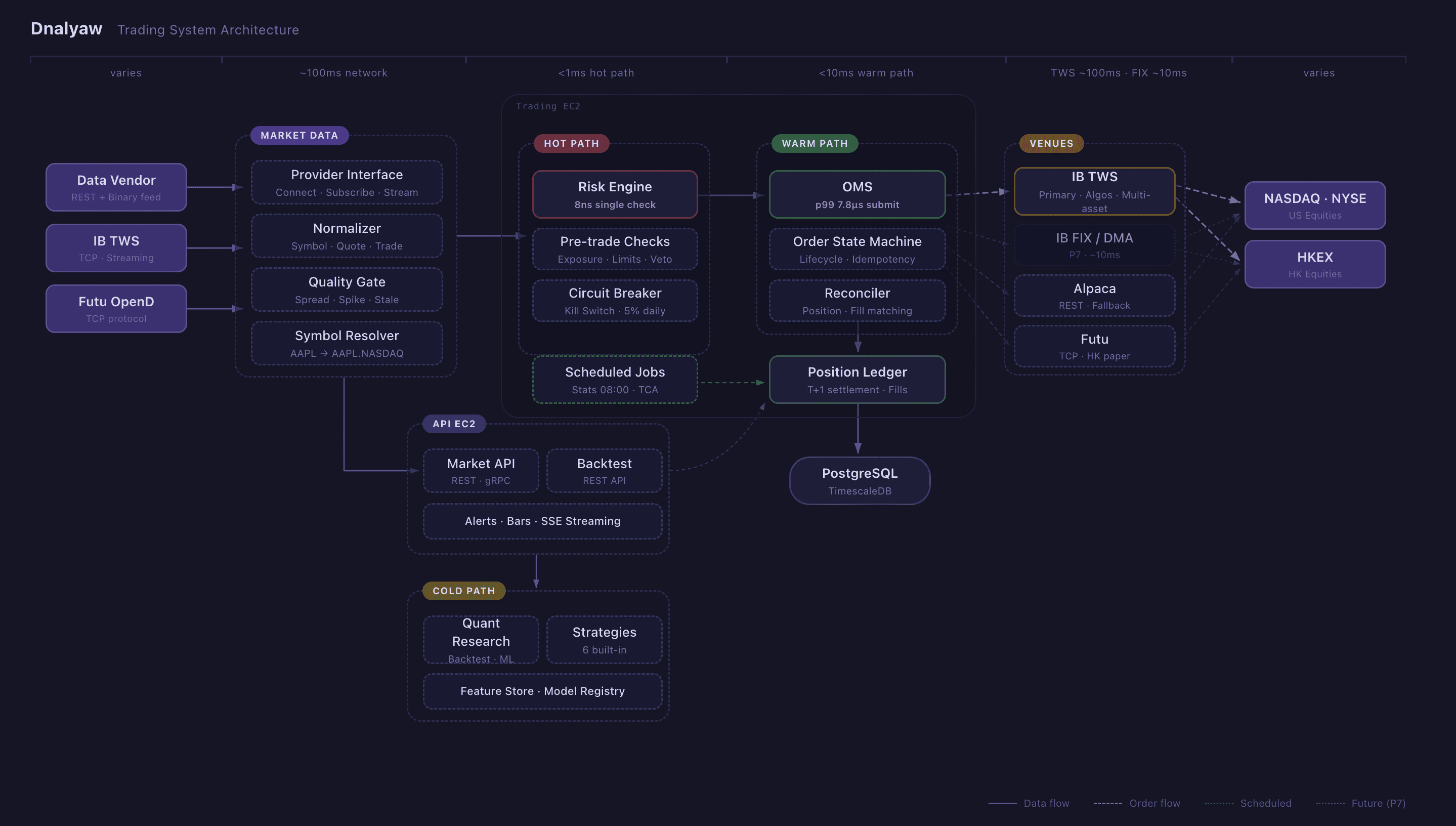
Rust:热路径(<1ms)
风险引擎和执行核心运行在 Rust。每一笔订单都必须通过交易前风险检查;基础校验可以在个位数纳秒内完成,即便有数百个未平仓持仓,也能保持在亚微秒级。这些是 Criterion.rs 在实际生产风险引擎上的测量结果。
为什么是 Rust?因为它有内存安全,又没有垃圾回收暂停。当你在每一笔订单上检查风险限额时,Java 或 Go 里的 10ms GC pause 意味着 10ms 内订单会排队等待、未经检查。Rust 的 ownership model 直接消除了这个问题。风险引擎在热路径上零分配。
风险引擎还实现了一个 kill switch——一个可以在微秒内平掉所有持仓并进入 reduce-only 模式的断路器。它有一条直连券商的绕行路径,意味着即使 Go orchestrator 完全宕机,它也能紧急关闭持仓。
Go:温路径(<10ms)
订单管理系统、策略编排、API 层和实时监控 TUI 都运行在 Go。Goroutine 和 channel 非常适合这个工作流:接收市场数据,分发给策略,收集目标组合,通过风险系统路由,管理订单生命周期。
OMS 实现了 p99 订单提交 228 微秒,吞吐量 907 orders/second——完全落在我们 <1ms 的目标内。订单状态机处理完整生命周期:new、submitted、acknowledged、partially filled、filled,并带有幂等保证和自动券商状态对账。
Go 正好卡在 Rust 的极致性能和 Python 生态之间的最佳平衡点上。它快到温路径不会成为瓶颈,又足够高效,让业务逻辑可以快速迭代。
Python:冷路径(async)
研究、回测、ML/RL 模型训练和 LLM 集成都在 Python 里。这里开发速度比执行速度更重要。策略库横跨几十个活跃系统化策略和数百个底层特征:经典因子(quality、value、momentum、low-vol)、统计套利(pairs、cointegration、cross-asset mean reversion)、微观结构、事件驱动、另类数据信号;研究 pipeline 的设计目标是持续引入和淘汰特征。广度是有意为之:没有任何单一特征是承重梁,也没有任何单一策略承载整个组合。
Python 策略不会直接生成订单。它们输出目标组合权重,通过 gRPC 流向 Go 执行层。这个隔离非常关键:Python 策略里的 bug 可能生成糟糕的 targets,但它在物理上无法绕过风险限额,也无法把格式错误的订单发给券商。
Python 层还承载回测引擎(用 FastAPI 包装供远程访问)、基于 TimescaleDB 的 feature store,以及连接我们的 LLM 编排平台用于情绪分析的桥接层。
风险管理:先防守,再进攻
如果只能选 Dnalyaw 里最重要的一个设计决策,我会选这个:风险引擎拥有绝对否决权,并且写在一种能让整类 bug 不可能出现的语言里。
四种风险决策
每笔订单都会收到四种响应之一:
- APPROVE:按请求继续
- REJECT:完全阻止——限额被突破、市场关闭,或集中度过高
- REDUCE:缩小订单规模(例如你请求 100 股,但敞口限制只允许 60 股)
- FLATTEN:紧急模式——关闭所有持仓,进入 reduce-only
REDUCE 是有趣的那个。多数风险系统是二元的——是或否。但实践里,一个策略可能方向正确,只是 sizing 过大。缩小订单保留 alpha 信号,同时强制执行风险边界。
硬编码限制(不可配置)
有些限制被刻意写成 Rust 里的不可变常量,而不是配置:
- 单一标的最大 5% 名义敞口
- 单一 sector 最大 25% 敞口
- 5% 日内回撤 kill switch
- 1% 单笔交易风险(Van Tharp floor)
为什么硬编码?因为凌晨 2 点,当一个持仓正在流血,而你的大脑告诉你“就这一次覆盖它”时,系统应该说不。可配置的限制会被重新配置。常量不会。
仓位 sizing:Half-Kelly + Van Tharp
我同时使用两个互补模型:
Half-Kelly(进攻——设定上限):Kelly criterion 给出长期复利增长下数学最优的下注比例。完整 Kelly fraction 是:
其中 是胜率, 是 reward/risk ratio。我们使用 half-Kelly ,来处理估计误差和 fat tails。它告诉你最多应该下注多少。
Van Tharp R-Multiple(防守——设定底线):
这确保单次亏损不会超过资本的 1%。它告诉你至少需要多少保护。
最终仓位永远取所有约束中最保守的一个:
进攻定义机会;防守定义生存。
多市场执行
Dnalyaw 运行一个双区域执行布局:美国基础设施部署在 NYSE 和 NASDAQ matching engine 附近,香港基础设施部署在 HKEX 附近。香港执行被刻意拆成两条独立场地路径,让我们在同一区域持续并行测量成交质量——这是一种廉价的执行 A/B testing,否则通常需要一个专门研究项目。架构也已经准备好扩展到期货和更多亚洲市场。
Provider 抽象
每个外部集成——数据源、券商、交易所——都通过干净的抽象接口接入。添加新的数据 provider,意味着实现 Connect、Subscribe 和 Stream。添加新的券商,意味着实现 SubmitOrder、CancelOrder 和 ModifyOrder。内部 canonical data model 会把一切归一化:AAPL.NASDAQ、0700.HKEX——同一格式,同一条 pipeline。
这很重要,因为真实世界很脏。一个 provider 发送二进制编码行情。另一个用 TCP streaming protocol。第三个用 REST。还有一个有自己的 protobuf-based protocol。所有这些都会在下游看到之前被归一化成单一 Quote struct。
质量门
原始市场数据并不可靠。Spread 会突然扩大。价格会 stale。数据 feed 会掉线。在任何市场数据到达策略层之前,它必须通过质量门检查:
- 异常 bid-ask spread(可能是坏 tick)
- Stale timestamp(feed 延迟或断线)
- 超过统计正常范围的 price spike(fat-finger trade 或数据错误)
一个坏 quote 漏过去,就可能触发一连串错误订单。质量门是很便宜的保险。
从回测到实盘:校准 Pipeline
这是大多数量化项目失败的地方。回测显示 Sharpe 2.0,你上线,现实交付 0.3。落差总是同一个:不现实的成交假设。
双层回测
Dnalyaw 运行两种不同回测模式:
- 快速 Python 向量化回测:用于快速策略迭代。几秒内用历史数据测试信号逻辑。
- Go OMS 集成回测:用模拟交易场地运行真实订单状态机。它能抓到只有生产中才会出现的 bug——partial fills、order rejections、settlement timing。
现实成交建模
回测成交模型包含:
- Bid-ask spread slippage:你总是要跨过 spread
- 基于成交量的市场冲击:使用 Almgren-Chriss 平方根冲击模型 ——你自己的订单会让价格朝不利方向移动
- 限价单成交概率:不是每个 limit order 都会成交
- 执行延迟:用实际测量延迟校准的 log-normal distribution
生产前校准
在任何策略获得资金配置之前,它会并行跑在实时市场数据上,并把自己的建模 P&L 持续和实盘执行本应产生的结果对标。系统在四个维度追踪 drift——日 P&L、Sharpe ratio、成交率、平均滑点——并把任何实质性分歧标出来供审查。
分阶段资本部署
资本配置遵循严格流程:validation → calibration → limited allocation → full allocation。每个阶段都有显式的量化毕业标准。策略不会因为回测好看就晋级;它们晋级,是因为实时执行在容忍范围内匹配模型预期。
AI 层:数百个输入之一
这里开始有趣,也是在这里我不同意多数“AI trading”叙事。
LLM 是特征来源,不是护城河
Dnalyaw 里最重要的 framing 之一是:LLM 生产特征,但不生产 alpha。每个把 OHLCV 数据喂给 GPT 然后问买卖信号的人,都在做同一件拥挤且容易复制的事——alpha 接近于零。语言模型提供的任何 edge,一旦它存在于别人也能调用的 API endpoint 上,就会消失。
语言模型真正有用的地方,是把非结构化数据转成数值特征,并加入和其他所有特征相同的 feature store。10-K filings 变成 lawsuit-risk scores。业绩电话会 transcript 变成 tone-shift vectors。Insider filings 变成 sentiment numerics。管理层变动变成 categorical feature。它们和基于价格、成交量、微观结构、另类数据的特征一起进入 feature matrix——没有对订单路径的特权访问,也没有叙事式判断。
这就是为什么护城河不是 LLM。护城河是一个 pipeline,能让来自几十种异构来源的数百个特征汇入同一个 research-to-execution loop。单独的 LLM 是商品。LLM 作为垂直整合系统内部众多特征生产者之一,才是 leverage。
在 Dnalyaw 里,LLM 和 agent 层通过 Shannon 编排——这是我们的 multi-agent platform——并有严格架构边界:
生产级 Multi-Agent 平台:使用 Rust、Go 和 Python 构建,用于确定性执行、预算强制与企业级可观测性。
LLM 和 agent 可以生产什么:从非结构化来源 numericize 出来的特征——filings、calls、news、alt-data、transcripts
LLM 和 agent 不能做什么:生成订单、决定仓位、修改风险参数、覆盖 stop-loss,或以任何方式触碰执行路径
这不是 policy,而是 architecture。LLM 输出只是大型 feature matrix 里的额外列。决定组合持有什么的,是确定性量化 pipeline,而不是语言模型。
用 RL 决定交易动作
信号生成——alpha factors、技术指标、LLM sentiment scores——来自量化研究层。RL agent 的工作不同:它把这些信号作为 state 的一部分消费,并决定如何对它们采取行动。pipeline 把这个问题建模成一个 Markov Decision Process:
- State:市场 regime(VIX、趋势指标)、组合状态(杠杆、回撤、Sharpe)、单标的特征(价格、波动率、RSI、来自 LLM 的情绪分数)、pairs 特征(spread z-score、cointegration)
- Action:目标组合权重——组合应该是什么样子,而不是单个订单
- Reward:一个把收益和风险纪律平衡起来的加权组合:
RL agent 输出的是 TargetPortfolios,执行层负责最优地从当前持仓转到这些目标——处理 order routing、partial fills 和 settlement。这种隔离意味着 RL agent 只专注于一个决策:给定这些信号和这个组合状态,我应该持有什么?
我们正在探索 PPO(对非平稳市场更稳定)和 SAC(数据昂贵时 sample-efficient),并每 30 天滚动 retraining 来处理 regime change。
TensorLogic:RL 背后的推理引擎
上面的 RL pipeline 需要的不只是模式匹配——它需要对市场结构进行推理。这就是 TensorLogic 出场的地方。
Tensor Logic 的 Python 实现:一种统一 AI 编程语言,通过张量方程结合神经与符号推理。
TensorLogic 是我基于 Pedro Domingos 的论文 “Tensor Logic: The Language of AI” 构建的框架。它把符号推理和神经学习统一到同一个计算基底里——张量方程。一个逻辑规则,比如 ,会变成一次矩阵乘法:。一切——逻辑、attention、composition——都归约到同样的张量操作。
这对量化交易为什么重要?传统 RL agent 是纯神经的——它们从数据里学习模式,却无法强制执行逻辑约束,也无法解释自己的推理。纯规则系统又很脆,无法适应变化。TensorLogic 同时给我们两者:
Boolean mode 用于硬交易约束:市场 regime 规则、持仓限制、风险边界被表达成严格逻辑约束——没有幻觉,没有近似。当系统说“这违反 dollar neutrality”时,它是可证明正确的。
Continuous mode 用于学习:标的、sector 和宏观因子之间的关系会变成可学习的 embedding matrices。评分函数 让模型发现潜在关系——比如哪些 sector rotation 预示着哪些后续变化,或者 VIX regime shift 如何沿相关 pairs 传播——而不需要人预先告诉它这些模式存在。
双模式架构直接映射到 Dnalyaw 的延迟层级。训练时,RL agent 在 continuous mode 下运行,通过 reward function 上的 gradient descent 学习组合权重策略。实盘 inference 时,关键约束切换到 Boolean mode——保证无论神经组件建议什么,学到的 policy 都无法违反风险限额。
最强大的能力是通过 RESCAL tensor factorization 做predicate invention。给 TensorLogic 一个包含标的关系、宏观指标和历史 regime label 的 knowledge graph,它会自主发现潜在因子——比如“momentum cluster”或“liquidity regime”这类未被显式定义的概念。这些被发明出来的 predicates 会成为 RL state space 的一等特征,让 agent 能推理的范围超出人定义指标。
这和把 OHLCV 数据丢给神经网络、希望它学到点什么,是根本不同的。TensorLogic 提供的是结构化、可组合、可解释的推理——而且模型大小只有 10-500KB,训练以秒计,效率比 LLM-based approaches 高出数量级。
Agent 辅助因子挖掘
一个更实验性的 pipeline 是:agent 提出因子假设(例如“R&D spend 相对于收入持续上升的公司,未来 6 个月跑赢”),backtesting validator 用历史数据测试它们,然后一个 decay checker 使用 AST similarity analysis 检测这个因子是否过于接近已知拥挤因子。如果原创性分数低于 0.7,候选因子会在进入 feature store 之前被拒绝。
这里的 agent 是假设生成器,不是信号——每个提出的因子仍然必须像任何其他特征一样,通过回测、校准和分阶段 allocation pipeline 来证明自己。这是正面处理 alpha decay:在有效市场中,所有人同时发现的因子会失去 edge,所以系统会在接受一个新列进入 feature matrix 之前显式检查新颖性。
可观测性:内建,而不是后贴
Dnalyaw 的每个组件都在实现时包含可观测性。不是事后。不是下个 sprint。就在同一个 commit。
三大支柱:
- 结构化日志:带 correlation ID,可以追踪一笔订单从信号生成、风险检查、OMS、场地提交,到 fill receipt 的完整路径
- 指标(OpenTelemetry → Prometheus):延迟直方图、按状态/场地/标的统计的订单计数、敞口 gauge、P&L tracking
- 审计轨迹:一个不可变 PostgreSQL 表,捕获每一次状态变化,包括 timestamp、actor 和完整 payload。每个风险决策都包含决策时所有指标的 snapshot。
为了实时操作,我用 Go 的 bubbletea library 做了一个 terminal UI(TUI)——positions、live quotes、order book、risk dashboard、alerts、watchlists 都是 tabs。没有 web framework。多数自营交易 desk 使用 Grafana + custom terminal tools 是有原因的:它们快、可靠,而且 WebSocket 断开时不会崩。
到目前为止我学到的事
构建 Dnalyaw 强化了几个信念:
先构建执行,再构建策略。 没有可靠执行,你无法测试策略。大多数量化项目从模型开始,再把执行补上。这是反的。
回测永远会说谎。 不是因为它坏了,而是因为它无法建模一切。滑点、借券成本、规模化市场冲击、延迟——这些会叠加。Shadow trading 是解药。
对 alpha 的期待应该诚实。 在高效的美国市场里,stat-arb pairs trading 扣除成本后的现实年化回报上限大约是 5-10%。Sharpe 超过 1.0 已经不错。Sharpe 超过 2.0 就可疑(检查你的假设)。年化 15-20% 很优秀。如果你的回测显示 50%+,那一定有哪里错了。
edge 不在模型,而在执行。 Renaissance 的 Medallion fund 据说在执行成本优化上投入的工程精力,比 alpha generation 还多。任何 AUM 下,一个好 fill 和一个坏 fill 的差异,都会在数千笔交易里剧烈复利。
风险工程比 alpha 更重要。 一个普通策略配上防弹风控,可以活到下一天继续交易。一个 brilliant strategy 配上糟糕风控,最终会爆仓。这个不对称是绝对的。
下一步
Dnalyaw 每天运行在美国股票(NYSE/NASDAQ)和香港股票(HKEX)上,并在亚洲使用双场地执行来做独立成交质量 benchmark。当前投入方向:
- Feature store scaling:今天有数百个特征,pipeline 设计目标是摄入数千个特征,并全部保持 point-in-time correctness,避免 lookahead bias
- RL training pipeline 扩展:从最初 PPO/SAC baseline 走向能反映 regime shifts 的 calibrated environment simulators
- 中国 A 股扩展:80% 散户参与意味着相比机构主导的美国市场,alpha 机会明显更高;基础设施已准备好通过 Stock Connect 扩展
- Decision Transformer research track:return-conditioned policy generation,指定目标 Sharpe 后由模型生成达到它的动作
- 把 TCA 作为一等研究活动:每一次 fill 都会反馈进执行校准,让交易成本测量和信号研究同等重要
真正的测试不是回测。真正的测试是完整闭环——research、risk、execution、TCA——如何在全球市场里,跨数千笔实盘交易,日复一日地复利。
这是我 AI 量化交易系列的一部分。上一篇 AI 量化交易:从模型到量化基金 讲概念基础。关注我,后续会继续记录这个系统如何演进。