本文整理自《深度流形漫谈》里我和马远老师、石根华老师关于「AI 与数学」的一次对谈,背后是马远与石根华的 Deep Manifold 框架。它接着我此前在 神经网络的四重境界 和 DeepSeek V4 与流形撕裂 里立的"流形先验"往回追一层:这套数学到底是从哪里来的。
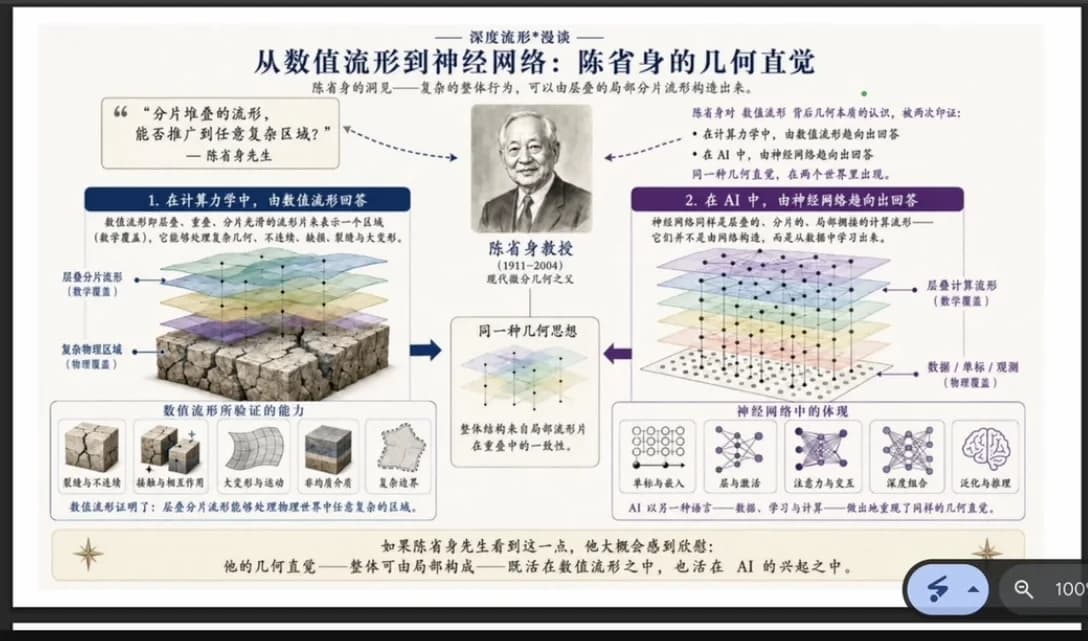
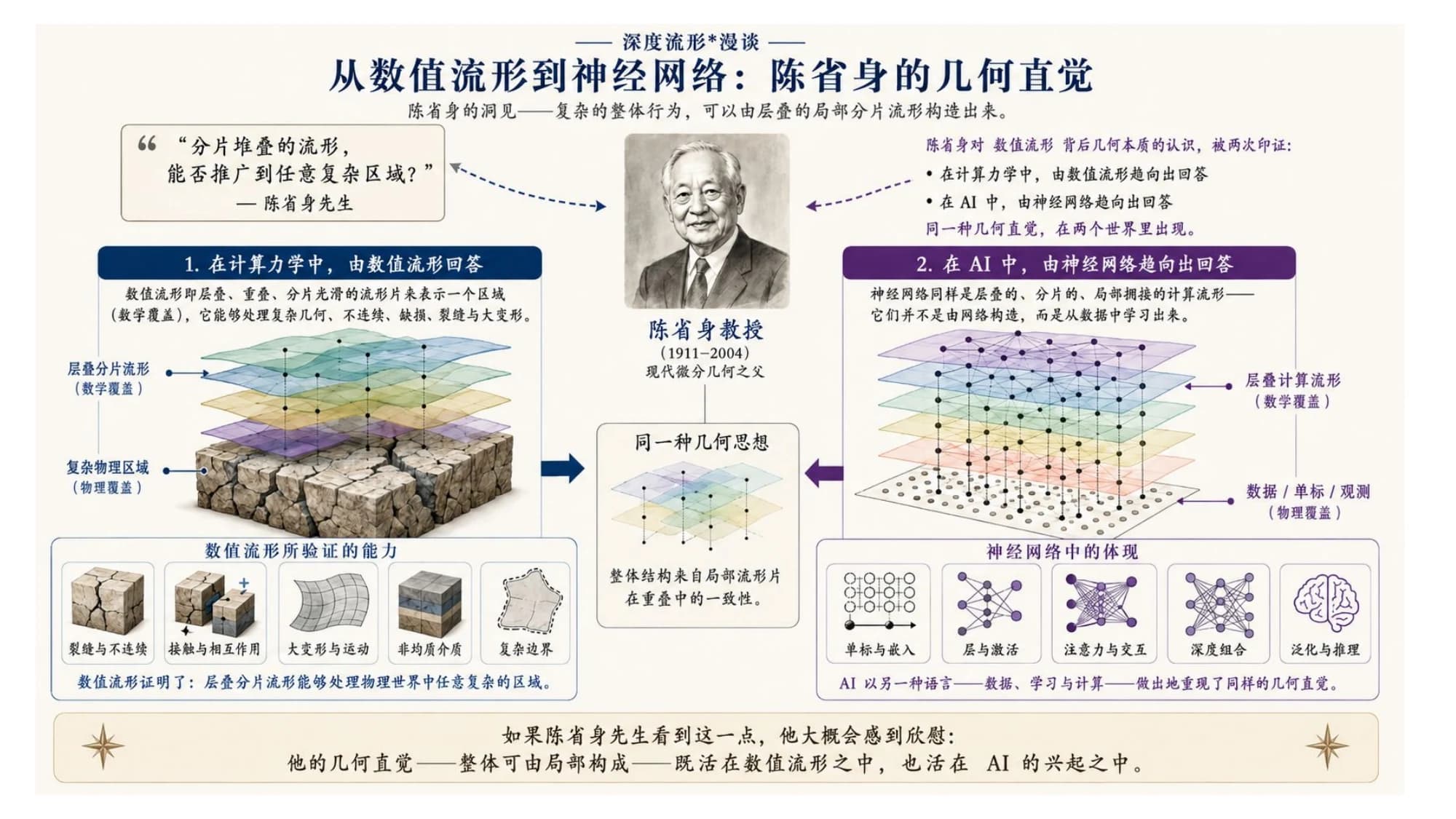
1991 年石根华提出数值流形法,得到过陈省身很高的评价。漫谈里提到,陈先生还留下过一个更大的疑问:
分片堆叠的流形,能不能推广到任意复杂的区域?
这是一个纯几何的问题。但它后来在两个毫不相干的世界里,各被回答了一次——一次在山体力学里,由石根华的数值流形法回答;一次在人工智能里,由神经网络回答。
更奇怪的是,两个答案是同一个。
而回答第二个问题的人——那些训练大模型的工程师——大多数并不知道自己在回答一个几何学家的提问。这篇文章想把这条线接起来:这套数学从黎曼一路走到神经网络,中间是怎么传下来的,又为什么会在 AI 里"无意中"重现。
在往下走之前,先立一把尺子。整场漫谈,其实绕着数学家的三个老梦想打转——
- 局部和整体:能不能用局部的小块,拼出整体的行为?
- 连续和非连续:连续的数学,怎么去算带裂缝、带断层的不连续世界?
- 正问题和反问题:已知原因求结果是正问题;从结果反推原因,是反问题。
这三对张力会在后面反复出现:流形是第一对的回答,数值流形是第二对的回答,而神经网络——是第三对的回答。
1. 流形这一脉:黎曼 → 庞加莱 → 陈省身
数学有一条很长的暗线,主题只有一句话:怎么用局部,拼出整体。
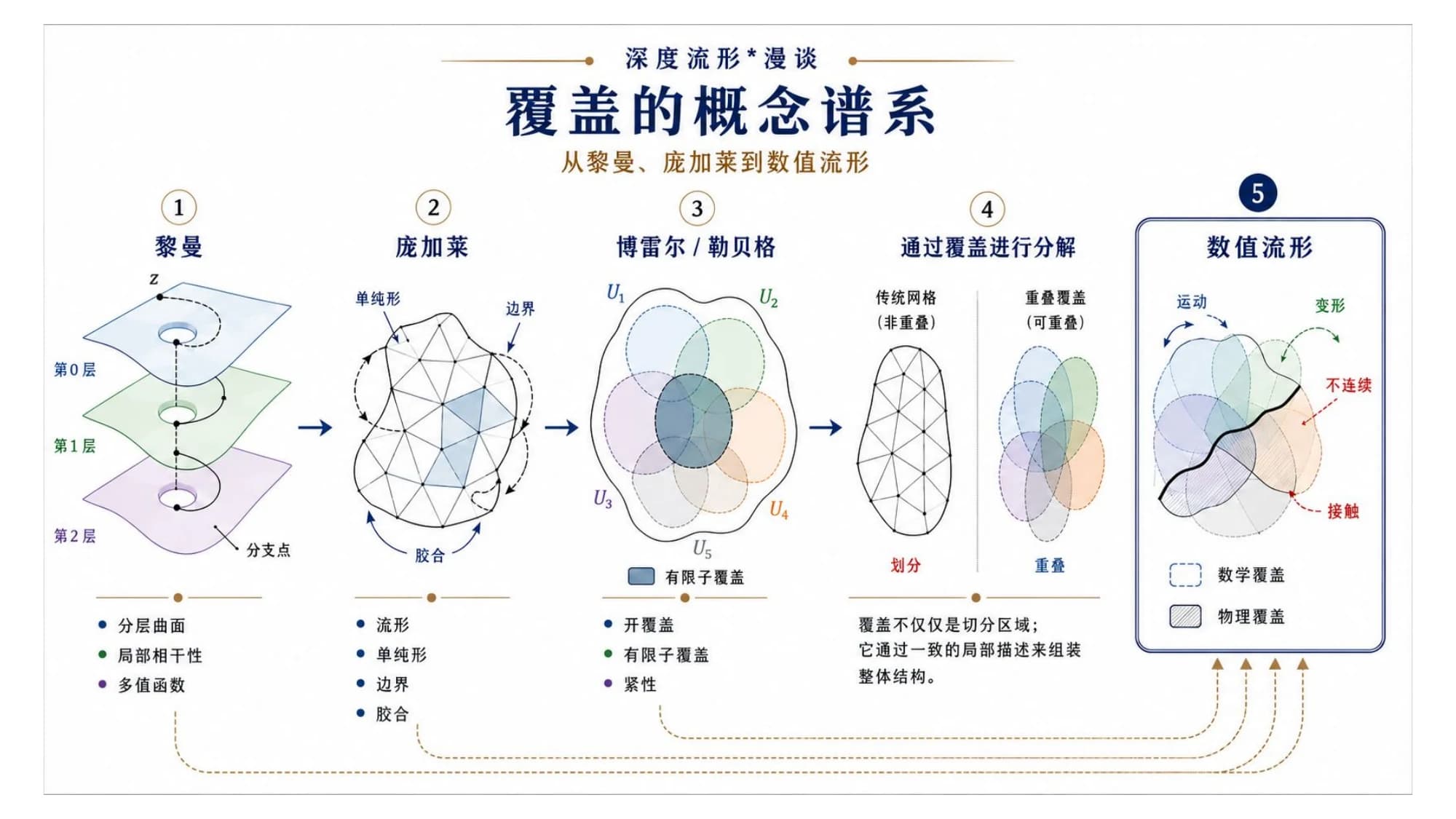
黎曼最早把这件事做实。他研究多值函数时发现,与其在一张平面上硬塞一个会自我冲突的函数,不如把它铺到分层的曲面上——每一层局部都规则、可微,整体却能容纳分支和奇点。这就是流形思想的种子:整体可以很复杂,局部必须足够简单,简单到可以做微积分。
庞加莱把它代数化。他用单纯形、边界、胶合,把"局部怎么拼成整体"变成可以计算的拓扑:一个流形,就是一堆局部小块按相容的规则粘起来的东西。"覆盖"这个词,从他这里开始有了精确含义。
中间还有博雷尔和勒贝格补上的一块地基——开覆盖、有限子覆盖、紧性。它回答了一个很要命的技术问题:无穷多个局部小块,什么条件下能用有限个就把整体盖住。没有这块地基,"局部拼整体"只是直觉;有了它,才是能算的数学。
到陈省身,这条线收口成现代微分几何。其实回头看,数学每隔一阵就会做一次类似的"广义化",节奏很像:
- 伽罗瓦把对称性变成可计算的对象——群论,这是数的广义化,从此"结构"本身成了研究对象。
- 庞加莱把空间的形状变成可计算的拓扑——1895 年的《Analysis Situs》,这是形的广义化,奠定了代数拓扑。
- 陈省身把这套几何推到全局——陈类、现代微分几何(1940 年代),这是函数的广义化:用基于覆盖系统的流形,让局部的几何量拼出整体的不变量,并对接真实世界的物理。
每一步都是同一个手法:先承认整体太复杂、没法直接处理,再退回局部去找规则,最后用"覆盖"这套语言把局部重新拼回整体。陈省身做的,是让这套几何语言强大到能承载微分方程、能对接真实世界的物理。江泽涵有一句话被反复引用——透过微分方程的窗子,数学家看到现实世界的光。陈省身这一步,等于把那扇窗子彻底擦亮了。
2. 中国的一脉:姜立夫 → 江泽涵、陈省身 → 姜伯驹、石根华
这条流形/拓扑的线传到中国,根子上有一个常被略过的名字:姜立夫。他门下出了两位日后改写中国几何拓扑的人——陈省身和江泽涵都是他的学生;而后来在不动点理论上走得很远的姜伯驹,是他的儿子。下面这几支看似分开的人,其实共一个源头。
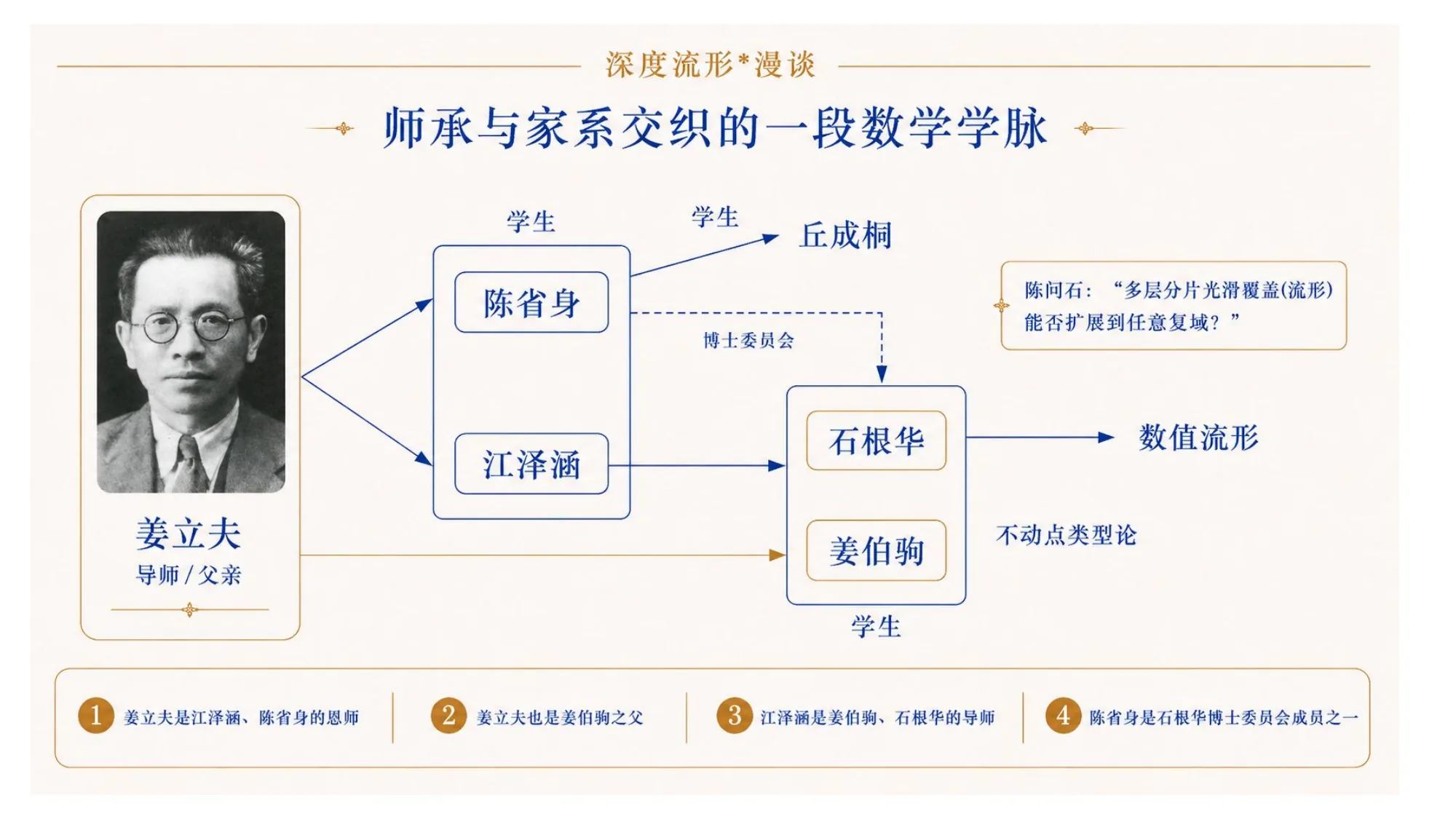
江泽涵把代数拓扑带进了北大,也带出了一整支人。
其中两支后来走得很远,而且都落在同一个题目上:不动点。
一支是姜伯驹,走的是纯粹的 Nielsen 不动点理论,是这个方向上国际公认的代表性工作。
另一支是石根华。1963 年他从北大数学系毕业、留校做研究生,师从江泽涵,主攻代数拓扑和不动点理论。他和江泽涵、姜伯驹一起发展了拓扑不动点理论,提出了"石氏类窝空间"与"石根华条件"。
值得一提的是,陈省身也是石根华博士委员会的成员之一——这条线又绕回了陈省身本人,也为后来数值流形法得到陈省身的高度评价埋下了伏笔。
到这里,石根华还是个标准的拓扑学家。真正特别的是他后来去的地方——他没有继续待在纯数学里,而是把这套不动点和流形的功夫,对准了岩石。
- 1968–1977 年,他做出了岩体稳定分析的赤平投影方法。
- 1980 年前后,系统完善了块体理论,发展出块体切割、单纯形积分,以及非连续变形分析(DDA)。这一段是他和伯克利的 Richard Goodman 一起做的,是岩石力学里绕不开的工作。
- 1991 年,他创立了数值流形法(NMM),拿到了陈省身的高度肯定。
- 2013 年,又系统构建了接触理论。
江泽涵那句"透过微分方程的窗子看现实",到了下一代手里被拆成了三个分工:陈省身说微分方程可以刻画现实(可以例);丘成桐发展了怎么例(几何分析这套办法);而石根华去回答最难的那一问——怎么在任意复杂的真实区域里,把它真的解出来。
一个研究不动点的拓扑学家,转身去算一块石头会不会塌。听上去像是离开了数学,其实他是把数学带去了一个数学家通常不去的地方。陈省身那个疑问——分片堆叠的流形能不能推广到任意复杂区域——石根华是在工程现场把它答出来的。
3. 一个疑问,两个世界同时回答
陈省身的洞见可以浓缩成一句:复杂的整体行为,可以由层叠的、局部的分片流形构造出来。
这句话被印证了两次。
第一次在计算力学里,由数值流形法回答。 真实的岩体是最不讲道理的研究对象:不连续、带裂缝、有断层、会大变形、还会接触挤压。古典的解析方法在这种几何面前基本失效。NMM 的回答是:用层叠的分片光滑流形去逼近它,再复杂的物理区域都能处理。陈省身的几何直觉,在工程里被证明是对的。
第二次在 AI 里,由神经网络回答。 神经网络也是层叠的、分片的、局部光滑的流形——只不过它们不是被谁设计成这样的,而是从数据里学成这样的。同一种几何直觉,在两个互不知情的世界里各长了一遍。
差别只在一个字:石根华是把流形选出来的,神经网络是把流形学出来的。结构一样,来源不同。
接下来几节,把这个"结构一样"讲实——它具体一样在哪。
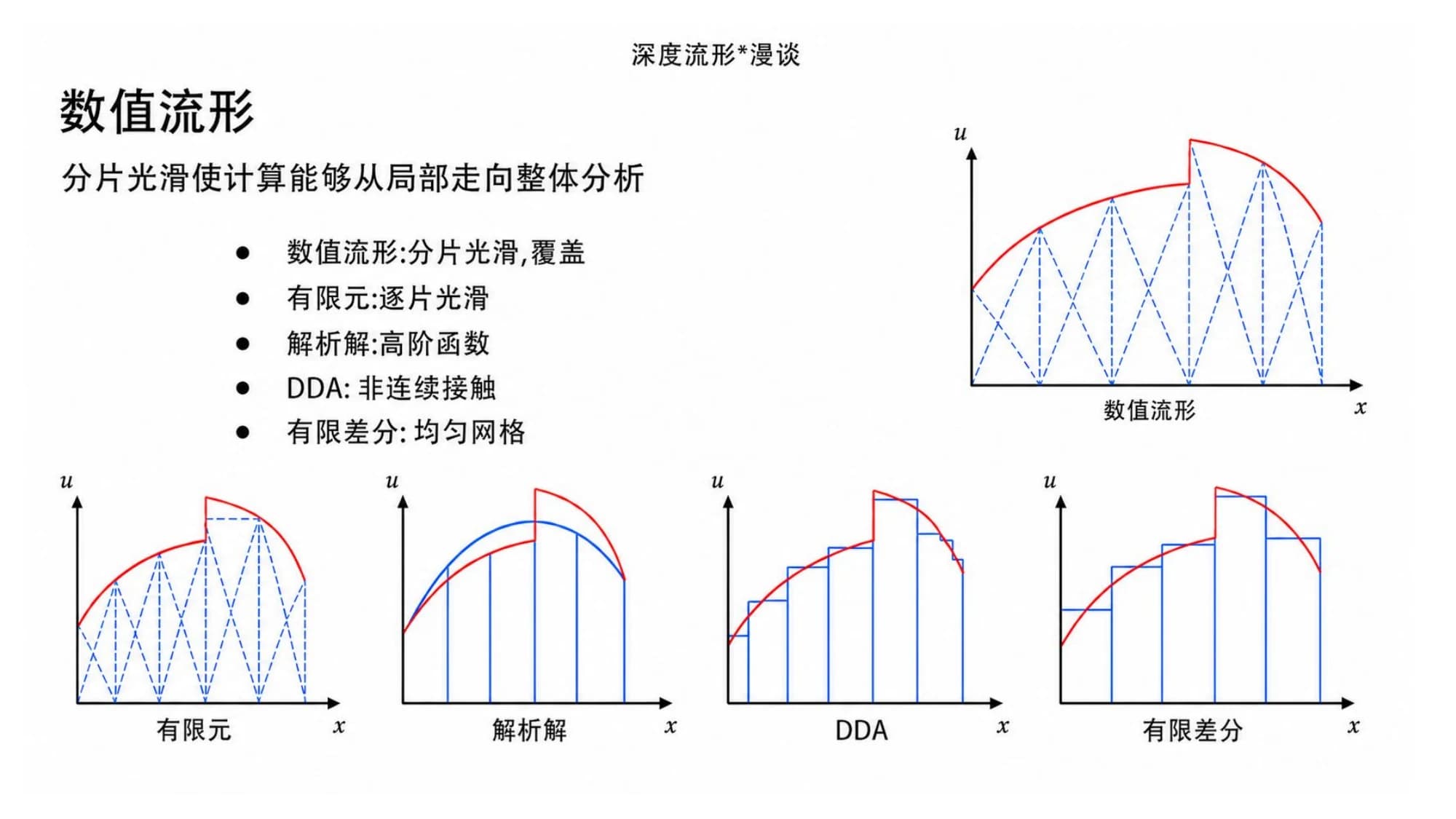
4. 数值流形:先看它在数值方法家族里的位置
陈省身那个疑问,石根华是用一套叫**数值流形法(NMM)**的方法答出来的。要看懂它,先把它放回数值计算的家族里。
工程上算一个连续体,常见的几条路子是这样分工的:
- 有限元:把区域切成一片片小单元,每片内部光滑——逐片光滑。
- 有限差分:直接铺一张均匀网格,在格点上做差分。
- 解析解:能写出高阶函数的闭式解,最干净,但只在规则区域里行得通。
- DDA(非连续变形分析):石根华自己更早的方法,专门处理块体之间的非连续接触。
- 数值流形:分片光滑 + 覆盖。它不要求一片片严丝合缝地拼,而是让一堆互相重叠的局部小块各带一个级数展开,再用"覆盖"把它们组织起来。
分片光滑加上覆盖,正好是从局部走向整体的那一步——这也是"数值流形"这个名字的由来。
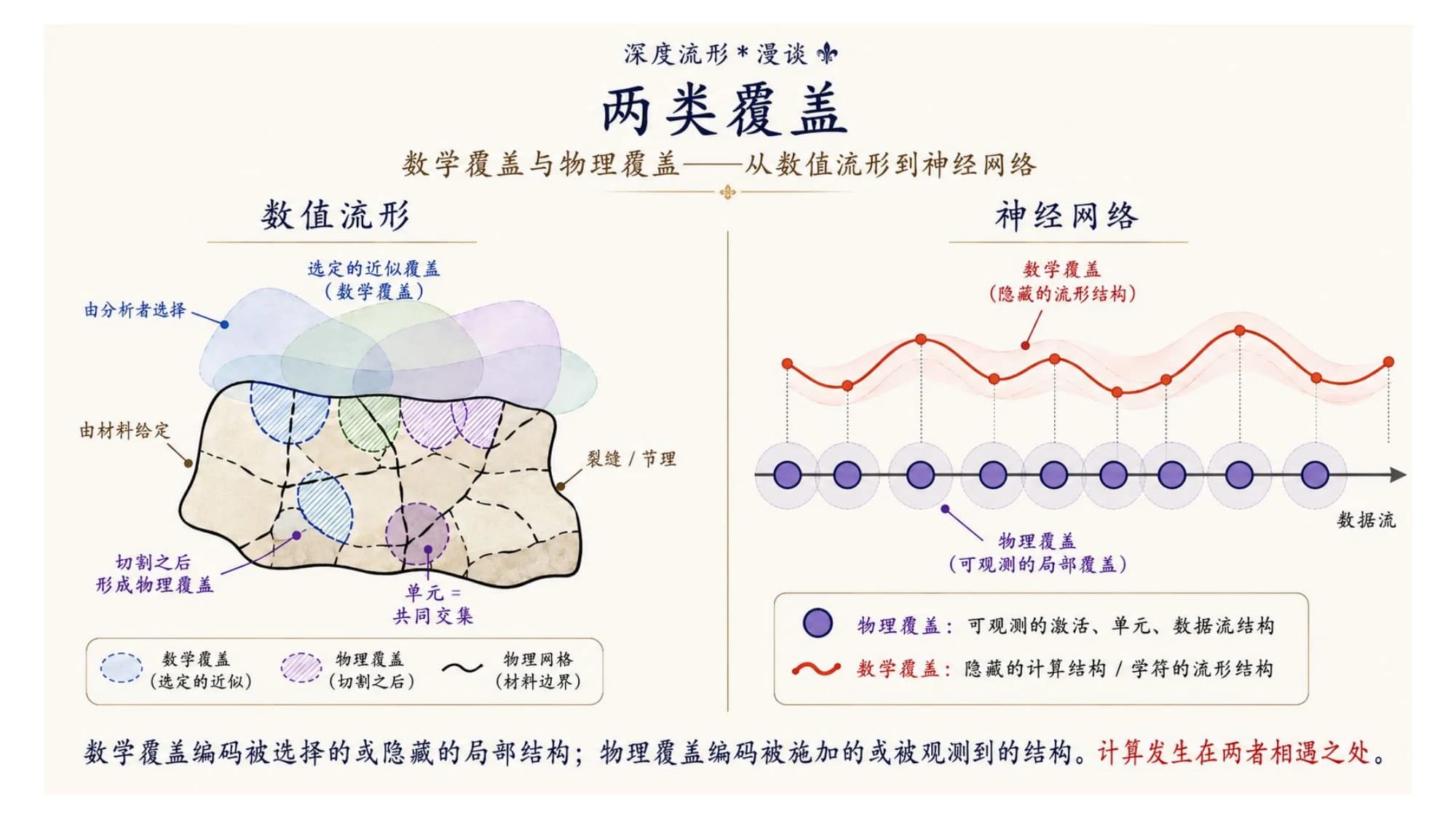
数值流形法最漂亮的一招,是它把"覆盖"拆成了两层。
数学覆盖:由分析者选定。它是一张连续、规则、光滑的数学骨架——一堆互相重叠的局部小块,每块上面带一个级数展开。它跟你研究的那块石头长什么样没关系,是你主动选的理想化的连续结构。
物理覆盖:由材料给定。真实的物体自带边界——材料的棱角、断层、裂缝、切割线。把这些切下去,就形成了物理单元。这是被施加的、可观测的结构。
关键在于单元 = 两者的交集。真正参与计算的那个单元,是一块数学小块和一块物理区域相遇的地方。
打个比方:数学覆盖像一张半透明、规则的网格膜,是你自己铺上去的、连续光滑的;物理覆盖是膜底下那块真实的、带裂缝的石头。把膜盖上去,膜和石头的交线,才是你真正去算的单元。石头裂了,膜不裂——裂缝的信息通过"交集"进入计算,却不破坏底下那张光滑的数学膜。
这就是 NMM 能从局部走到整体、能处理不连续、能同时算正问题和反问题的原因:它把"在哪里逼近"(数学)和"材料实际在哪里"(物理)分开,再让它们相交。
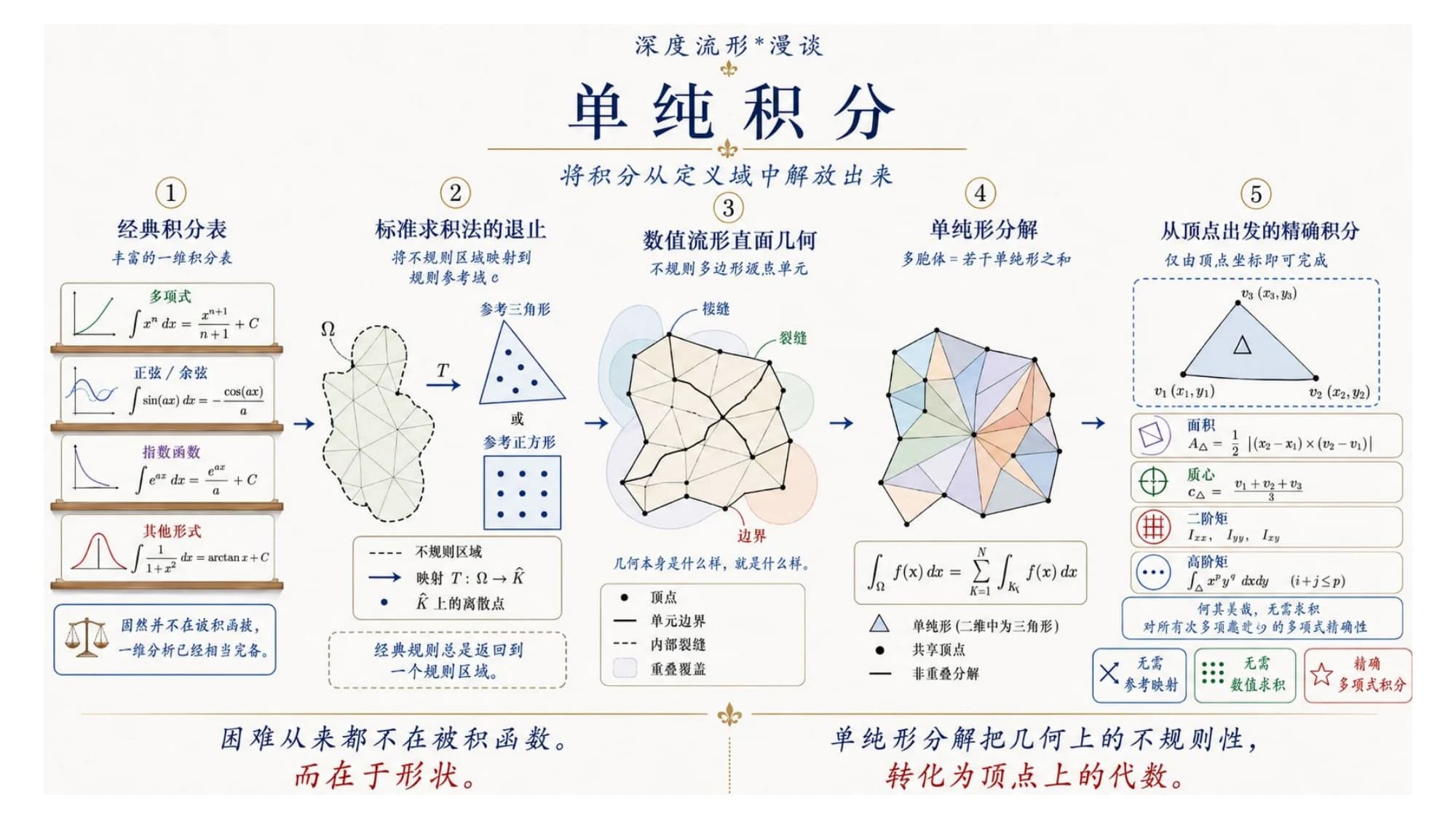
5. 单纯积分,和距离理论
NMM 还有一招很能体现石根华的风格:单纯积分。
经典积分有一张丰富的一维积分表——多项式、正弦余弦、指数,套公式就能积。问题从来不在被积函数,难的是形状:真实的区域是带洞、带裂缝的不规则多边形,标准求法只能先把它映射回一个规则的参考区域,再积。
石根华的做法是直面这个不规则的几何:把多边形单纯形分解成若干三角形(多边形 = 若干单纯形之和),再做"从顶点出发的精确积分"——只用顶点坐标,就能把面积、形心、二阶矩乃至更高阶矩精确算出来,不需要参考映射,也不需要数值求积。
一句话:单纯形分解把几何上的不规则性,转化成了顶点上的代数。 困难从来不在被积函数,而在形状——石根华把形状这一关,从几何问题降成了算术问题。
从等式到不等式。 还有一条线值得点一句。古典分析处理的是等式和连续;而真实世界里大量的关系是不等式——接触、距离、远近。石根华的接触理论(2013 年系统构建)研究的就是块体之间"碰没碰上、离多远"这类问题,它属于距离(接触)理论的范畴:度量空间里的 ε-覆盖,关心的是点与点之间够不够近。
这一点直接通到 AI:相似度、检索、对比学习,本质上都在算距离——两个向量够不够近、该不该归成一类。AI 里这套天天用的东西,落在数学上,正是石根华那套距离理论的范畴。
6. 同一套结构,出现在神经网络里
现在把这两类覆盖搬到神经网络上,会发现它严丝合缝地对得上。
- 物理覆盖,对应网络里可观测的东西:激活值、神经元/单元、数据流的结构。就像那块带裂缝的真实石头——你能测到它。
- 数学覆盖,对应网络里隐藏的东西:它从数据里学出来的那层流形结构,符号和计算层面的骨架。就像那张光滑的数学膜——只不过这一次,没有人去画它,是网络自己学出来的。
- 而计算,发生在两者相遇之处。和 NMM 一个原理。
具体到一个 token:它并不活在某一层上,而是活在一摞堆叠的流形层里;网络的第一层 FFN 投影,做的就是一次局部覆盖。一个 token 在多个流形层中被分别表示,整体行为从这些局部分片里拼出来——又是陈省身那句话。
写成公式,一个 token 的特征 ,第一层做的就是一次局部投影,再堆叠成深层:
前一步学到的是数学覆盖(局部的可学习流形),后面堆出来的激活值是物理覆盖(可观测的)。这恰好就是数值流形里"局部覆盖通过一次投影,成为堆叠的可学习流形"那一步。
| 数学覆盖 | 物理覆盖 | 计算发生在 | |
|---|---|---|---|
| 数值流形(山体) | 分析者选定的连续光滑覆盖 | 材料给定的边界、断层、裂缝 | 两者的交集 |
| 神经网络(AI) | 隐藏的、学到的流形结构 | 可观测的激活、单元、数据流 | 两者的交集 |
神经网络在没人告诉它的情况下,自己重建了石根华那套覆盖。它不是被设计成数值流形的,它是学成了数值流形。
而且它学的是关系,不是对象。 再追一层:神经网络从数据里到底学到了什么?不是数据本身,而是数据之间可计算的关系。
- 学习不会记住孤立的样本,它学的是样本之间的映射、差异与结构。
- 分类的依据不在对象本身,而在它们之间的关系——关系比对象更重要。
- 神经网络的激活是无属性的(propertyless):一个激活值不携带"它是什么"的内在属性,它只是某个关系网络里的一个坐标。
- 那靠什么把类别分开?靠计数——把差异落成数值,差异就变得可分。
用范畴论的话说,神经网络遵循的是"关系先于对象"的第一性原理:先有关系和差异,对象只是关系网络上的节点。这也解释了为什么同一套网络能把一个词和一张图片放进同一个空间——它们作为对象天差地别,但在关系结构里可以占同一个位置。这一点,下一节讲不动点时会再碰到。
7. 不动点:石根华的拓扑,和大模型的训练,是一回事
别忘了石根华的底色是不动点理论。这一节是这篇文章里我最想讲清楚的一层联系。
不动点是什么?给一个映射 ,那个满足 的点——映过去还是它自己——就是不动点。不动点理论问三个经典问题:
- 存在性:到底有没有解?
- 唯一性:如果有,是不是只有一个?
- 稳定性:解受一点扰动,还回得来吗?
这三个问题,正好是大模型训练每天在面对的问题,只是没人用这套词去讲。石根华他们这一脉研究的,正是不动点类的理论(The Theory of Fixed Point Classes)——不只问有没有解,而是刻画"解的结构"。
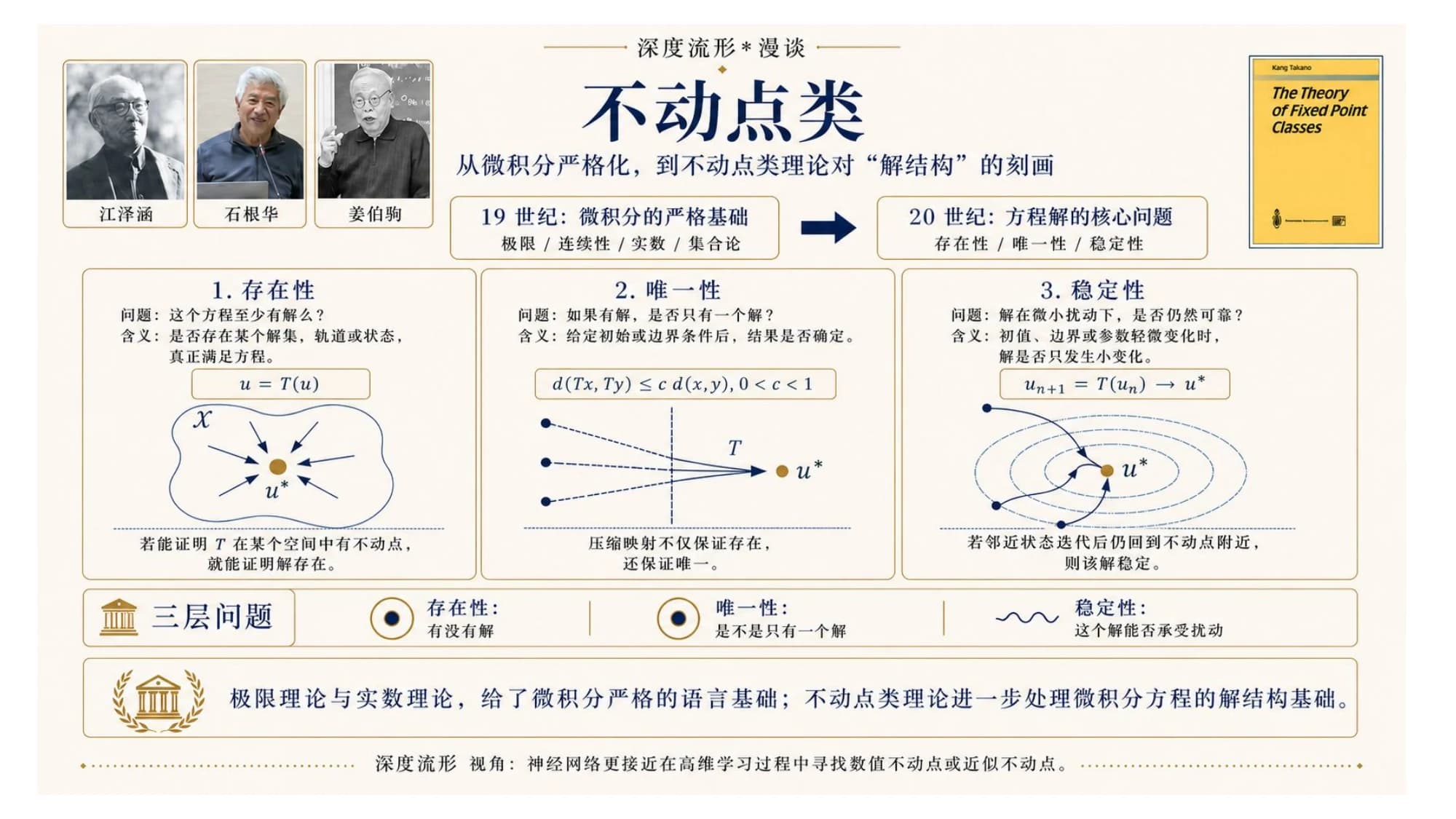
神经网络的学习,本质上是在高维空间里找一个(近似的)不动点。把它写成残差的形式:
当残差 趋于零,系统就"停"在了不动点上——它不再变化,学习收敛了。更妙的是不同模态共享同一个数值形式: 这个词,和一张狗的图片 ,被嵌入到同一个 的结构里,差异被折叠进同一套不动点的语言——这正是上一节"关系比对象更重要"的另一种说法。
把它写成可优化的形式,就是给残差套一个拉格朗日量:
训练就是去找 的那个临界点——也就是不动点。残差是优美的数学刻画,拉格朗日形式让它可计算。
再往上一层,不同的训练范式,对应着对不动点类的不同操作:
- 预训练:形成不动点类——在一片混沌里长出许多稳定吸引点。
- 指令微调:对齐这些类别——把目标类别挑出来、强化。
- 强化学习:驱动、扰动这些类别——把许多类别推得动起来。
所以石根华在拓扑里研究的不动点类,和大模型训练时在做的事,不是"像",而是同一套数学。一个在抽象空间里刻画解的结构,一个在高维参数里寻找数值不动点——本质上是一回事。这也是马远和石根华那个 Deep Manifold 框架的一句话总结:神经网络,是一种基于不动点理论的可学习数值计算。
8. 学习是反问题:另一条暗线
前面那条流形/覆盖的暗线,从黎曼一直走到神经网络。其实还有第二条暗线,平行地通到同一个地方——反问题。
正问题是已知原因求结果;反问题反过来:从观测到的结果,反推隐藏的结构。学习,本质上就是一个反问题——给你一堆数据(结果),求那个能生成它们的模型(原因)。
这条线也有自己的一脉传承:
- 约 1902,阿达马:提出"适定 / 病态"的判据——存在性、唯一性、稳定性。
- 1917,拉东:拉东变换,后来成了 CT 断层成像的数学地基——从投影重建结构,是最典型的反问题。
- 1943 / 1963,季霍诺夫:正则化,让病态的反问题在数值上变得可解。
- 1951,盖尔范德 & 列维坦:反问题的谱理论——从谱数据恢复算子。
- 1950s–60s,法杰耶夫:把反问题推向高维。

这一脉今天很少被 AI 圈提起,但大模型其实就站在它的延长线上:从海量观测里反推一个高维的隐藏结构。下一节讲"AI 为什么靠不住",靠的就是这条线上阿达马那个"病态"的判据。
9. 这也解释了 AI 为什么"靠不住"
把神经网络看成反问题、看成找不动点,还有一个直接的副产品:它解释了 AI 为什么这么不稳。
数学里有个判据叫适定性:一个问题要算得"干净",得同时满足存在、唯一、稳定。只要缺一个,它就自动被归为病态(ill-posed)。
而学习常常是个反问题——从观测到的结果,反推隐藏的结构——这类问题往往欠约束,容易在唯一性和稳定性上出问题,也就是偏"病态"。AI 表现出来的"锯齿状"(jagged,Joshua S. Gans 2026 年用过这个说法)——能在一个任务上惊艳,又在一个看起来更简单的任务上摔得莫名其妙——多少就是这种欠约束在表面上的样子。前面说过激活是"无属性"的;病态和无属性,正是从"数学家的三个梦想"出发去看 AI 时,最该盯住的两个毛病。
这件事在大模型的损失曲线上看得最直接。训练初期 loss 快速下降,之后就进入一段长长的、上下抖动(zig-zag)的缓慢下降——它不像一条干净的曲线收敛到底,而是在不动点附近反复横跳。
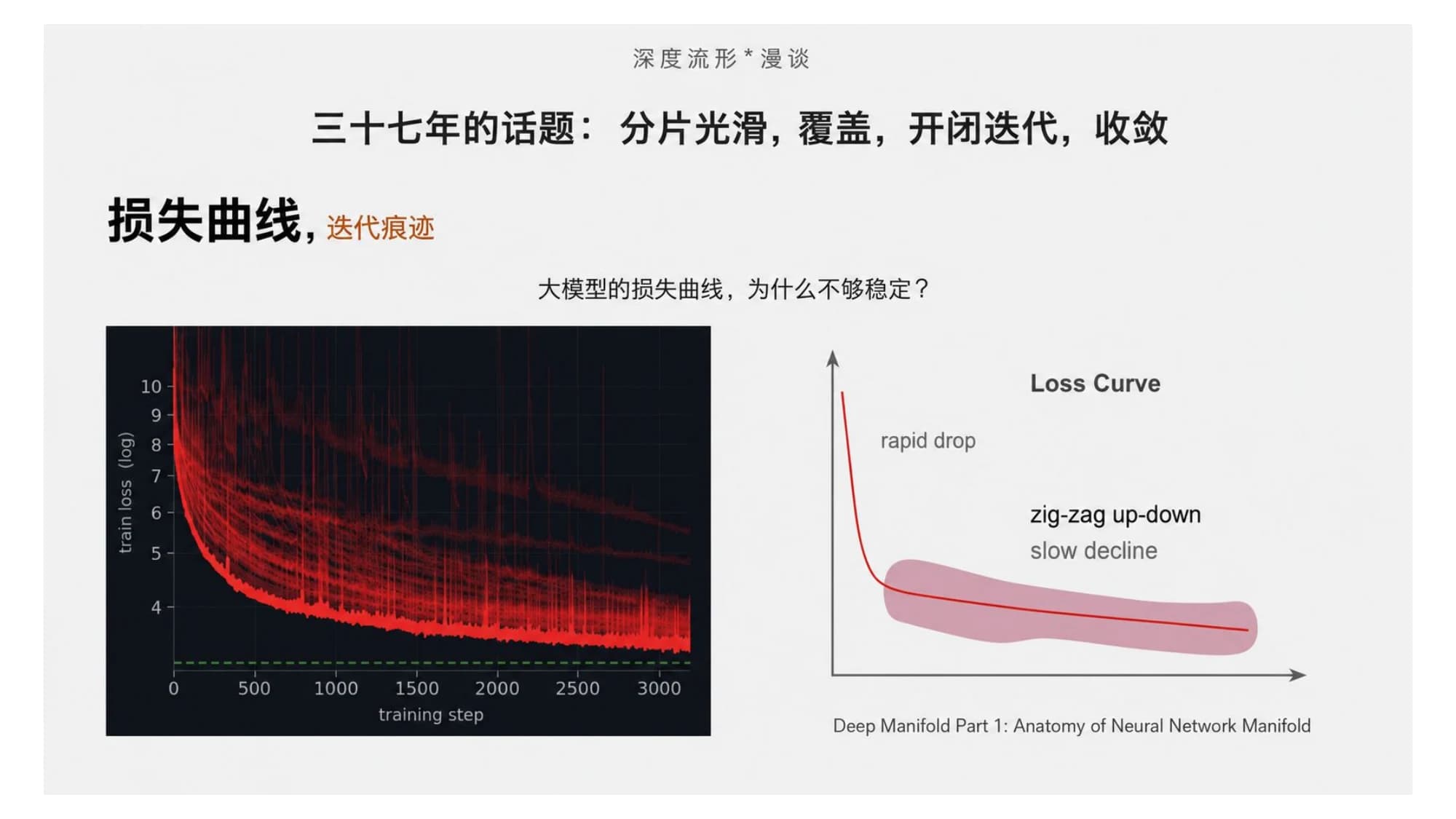
这正是石根华他们说的"三十七年的话题":分片光滑、覆盖、开闭迭代、收敛。一个迭代系统在找不动点,找的过程本就不平滑;而当这个反问题还是病态的(欠约束),抖动就更明显。大模型 loss 曲线为什么不够稳,根子在这里。
反问题数学早有一味药:正则化——给欠定的问题补上额外的约束、先验和边界,把它拉回到可解、稳定的范围。今天我们给大模型配的那一套,是同一味药的工程版:用脚手架(scaffolding)稳住多步推理,用检索和工具给它锚定外部事实,用约束框架(harness)圈住输出的边界。说到底,都是在给一个欠约束的内核补上外部约束,让它跑得更稳、更可靠。
而这恰好又回到了石根华的老本行。岩体本身就是不连续、带裂缝、不稳定的——工程师从来不去消灭裂缝,那不可能;他们给岩体配支护,让它带着裂缝照样稳住。给大模型配脚手架,和给山体配支护,是同一种思路。一个欠约束的内核,外面套一层工程的约束,才跑得稳。
10. 马远:站在两个世界中间的人
这条线能被看见,靠的是一个同时在两个世界里待过的人——马远老师。
他 1986 年从同济大学建筑工程系毕业,很早就做过人工智能辅助工程制图。1989 到 1999 年师从石根华,发展了 Fourier 级数富集的数值流形和高阶非连续变形分析。后来他转进 IT,在微软研究院做过大数据和人工智能。
这份履历的关键,不是它长,而是它横跨:一头是石根华的工程数值方法,一头是现代 AI。
这种对应——神经网络和数值流形是同一套结构——没有一个两边都熟的人,是看不见的。只懂数值流形的人,不会去读 Transformer 的论文;只懂深度学习的人,没听说过 NMM 和不动点类。要让一个 1991 年的岩石力学方法,和一个 2020 年代的大模型对上号,得有人同时在两张地图上站过。2024 年起,马远和石根华正式合作,把这件事写成了 Deep Manifold 理论。

11. 一个老传统:推进数学的,常常不是数学家
还有一层值得一提。回头看,把数学往前推的人,很多并不是职业数学家。
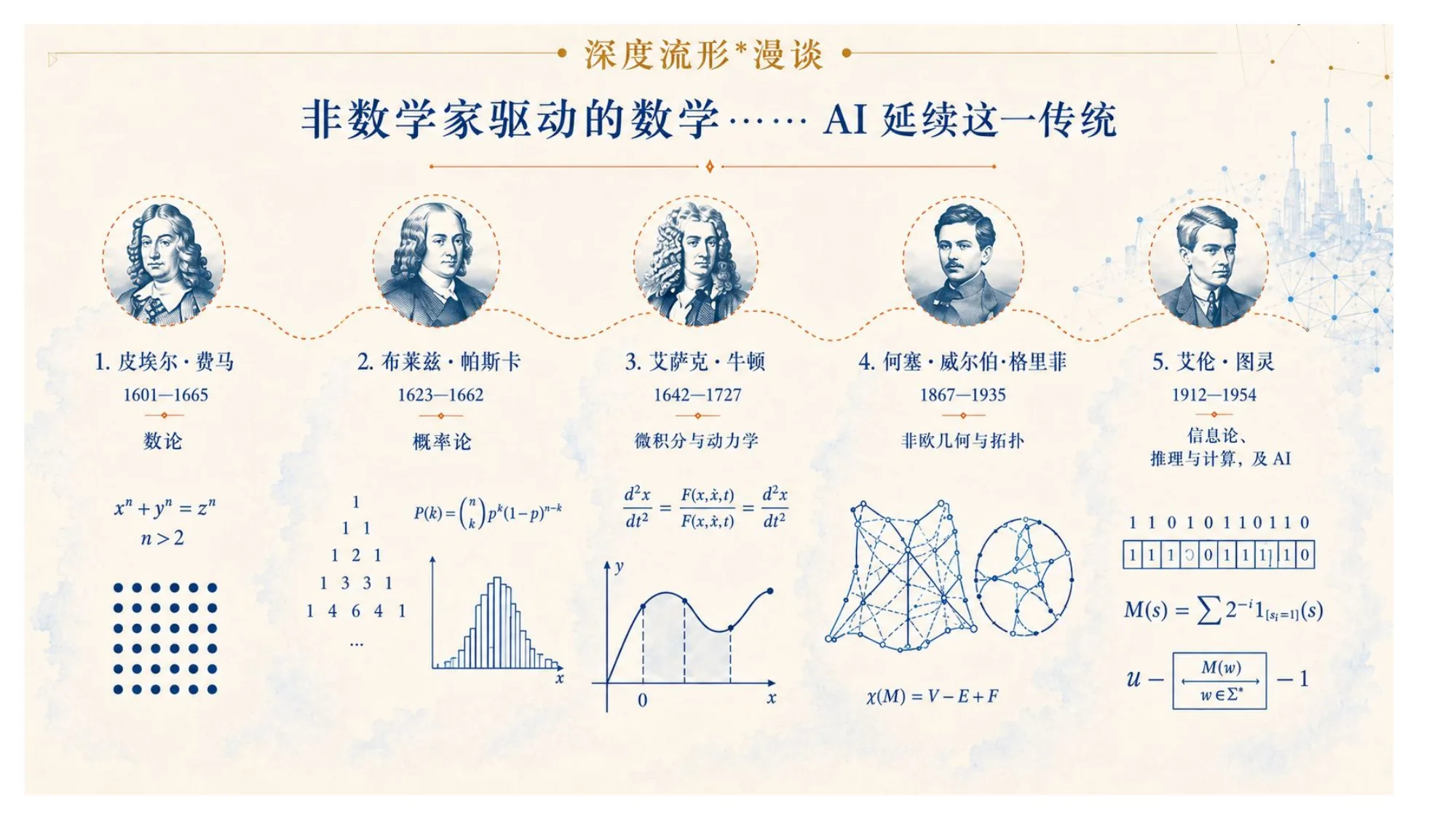
费马是法官,数论是他的业余爱好;帕斯卡、牛顿的动机一半在物理;图灵想的是计算与机器。他们带着各自领域的问题闯进数学,反而开出了新方向。今天训练大模型的工程师也是如此——他们追的是预测精度和工程指标,不是几何定理,却在无意中,把流形与不动点这套数学又往前推了一把。AI 不是这个传统的例外,而是它最新的一例。
还可以再分一刀。推进数学的人里,大致有两种:
- 理论的天才:江泽涵、陈省身——对各种猜想本身的研究,把数学往前推。
- 实践的地才:石根华,以及伯克利的 Goodman(1935–2025)、吕祖衍这些把数学带进工程现场的人——他们不证定理,他们去算一块石头会不会塌。
AI 强大又脆弱的两面,恰好需要这两种人一起看:天才看它的结构,地才看它在真实世界里稳不稳。
12. 真实世界里的深度流形
漫谈的最后,把镜头拉远了一点:这套"深度流形"的视角,第一性的落点是真实世界——真实的数据、真实的问题、真实的学习与发现。
陶哲轩有一句话被引在这里:"数学不是关于数字、方程、计算或算法——它是关于理解。" 深度流形想做的,正是去理解神经网络背后那套数学,而不只是把它当成一个能调参的黑箱。
从这个视角看出去,有几件事会变得清楚:
- 反问题、泛化、因果:学习是反问题;泛化能力是它能不能稳;因果可以看成一种有序的流形几何。
- 正问题可能比反问题更迷惑:看似简单的正向任务,反而最容易让模型栽跟头——这正是"锯齿状"的来源。
- 训练范式有了数学定义:预训练 / 指令微调 / 强化学习,对应着对不动点类的三种操作,不再只是工程经验。
把神经网络放回数学的长河里,它不是一个突然冒出来的怪物,而是黎曼、庞加莱、陈省身这条流形暗线,和阿达马、拉东、季霍诺夫那条反问题暗线,在 2020 年代汇到一起的样子。
结论
- 流形/覆盖是一条长线:黎曼 → 庞加莱 → 陈省身,主题始终是"用局部拼出整体"。
- 这条线传到中国:江泽涵 → 姜伯驹、石根华,把不动点和流形接在了一起。
- 陈省身的疑问被两个世界同时回答:山体力学(NMM)和 AI(神经网络),答案是同一个。
- 关键机制是两类覆盖:数学覆盖(选出/学出的光滑结构)与物理覆盖(给定/可观测的结构),计算发生在它们的交集。
- 学习就是找不动点:不动点类对应预训练 / 微调 / 强化学习——这和石根华在拓扑里做的,是同一套数学。
- 学习偏"病态"(欠约束的反问题):正则化、检索、工具、约束框架(harness)给它补上外部约束——和给山体做支护,是同一种思路。

漫谈里有一句话我很喜欢——一块石头掉下来,最后总是会停下来的。 一个迭代系统,最后会停在它的不动点上。神经网络一边追着预测精度,一边在无意中,把黎曼、庞加莱、陈省身、江泽涵、石根华这一脉的数学,又往前推了一把。
如果陈省身看到这一点,大概会感到欣慰:他那个几何直觉——整体可由局部拼成——既活在数值流形里,也活在 AI 的兴起之中。