Most agent frameworks give you building blocks. Shannon gives you a production system.
Production-Grade Multi-Agent Platform - Built with Rust, Go, and Python for deterministic execution, budget enforcement, and enterprise-grade observability.
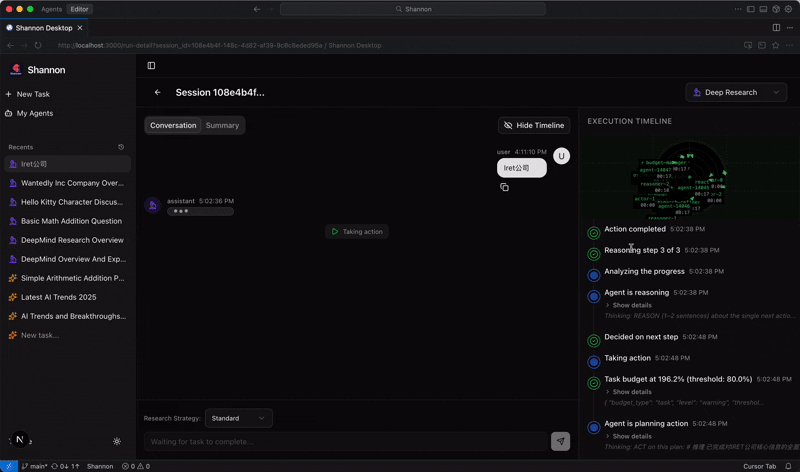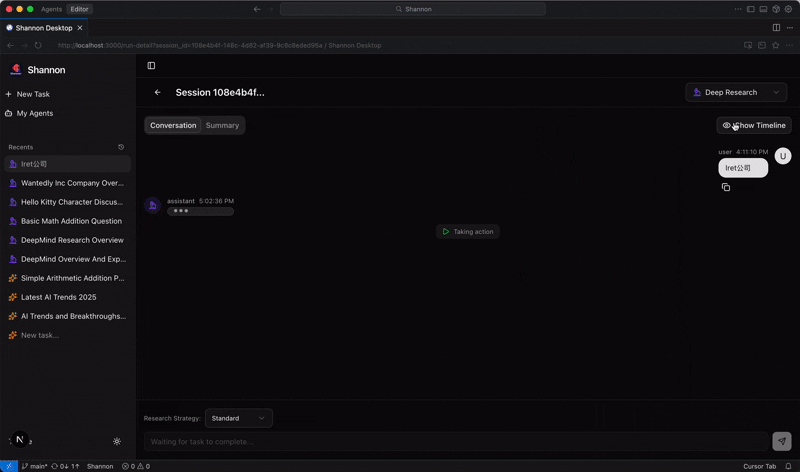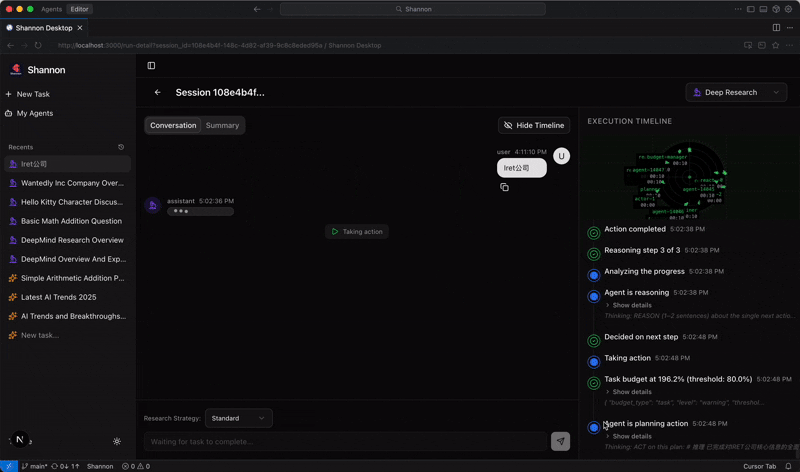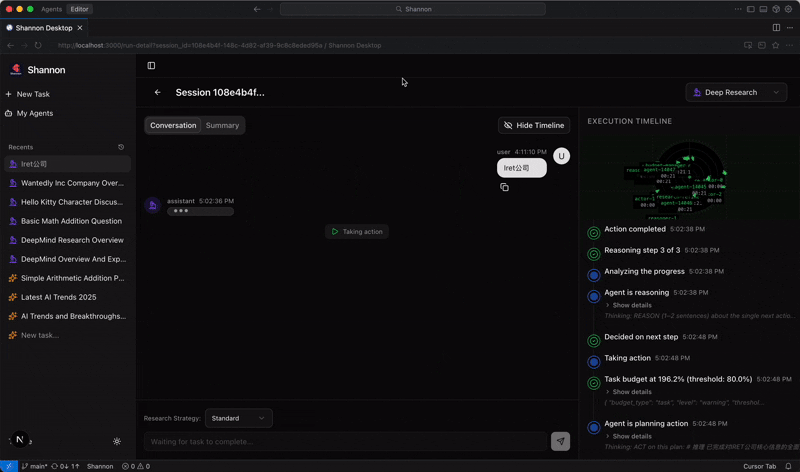
The Production Problem
Building AI agents is easy. Running them in production is hard.
After prototyping with LangGraph, CrewAI, or similar frameworks, teams hit the same walls:
- Runaway costs: A single misconfigured agent can burn through thousands of dollars in hours
- Non-deterministic failures: When an agent fails at 3 AM, how do you reproduce the bug?
- Security nightmares: Agents that execute code or call APIs become attack vectors
- Observability gaps: Where did the tokens go? Which agent failed? What was the decision path?
- Vendor lock-in: Changing LLM providers means rewriting integration code
Shannon was designed from day one to solve these production problems—not as afterthoughts, but as core architectural decisions.
Architecture: Why Three Languages?
Shannon's hybrid architecture isn't accidental. Each language handles what it does best:
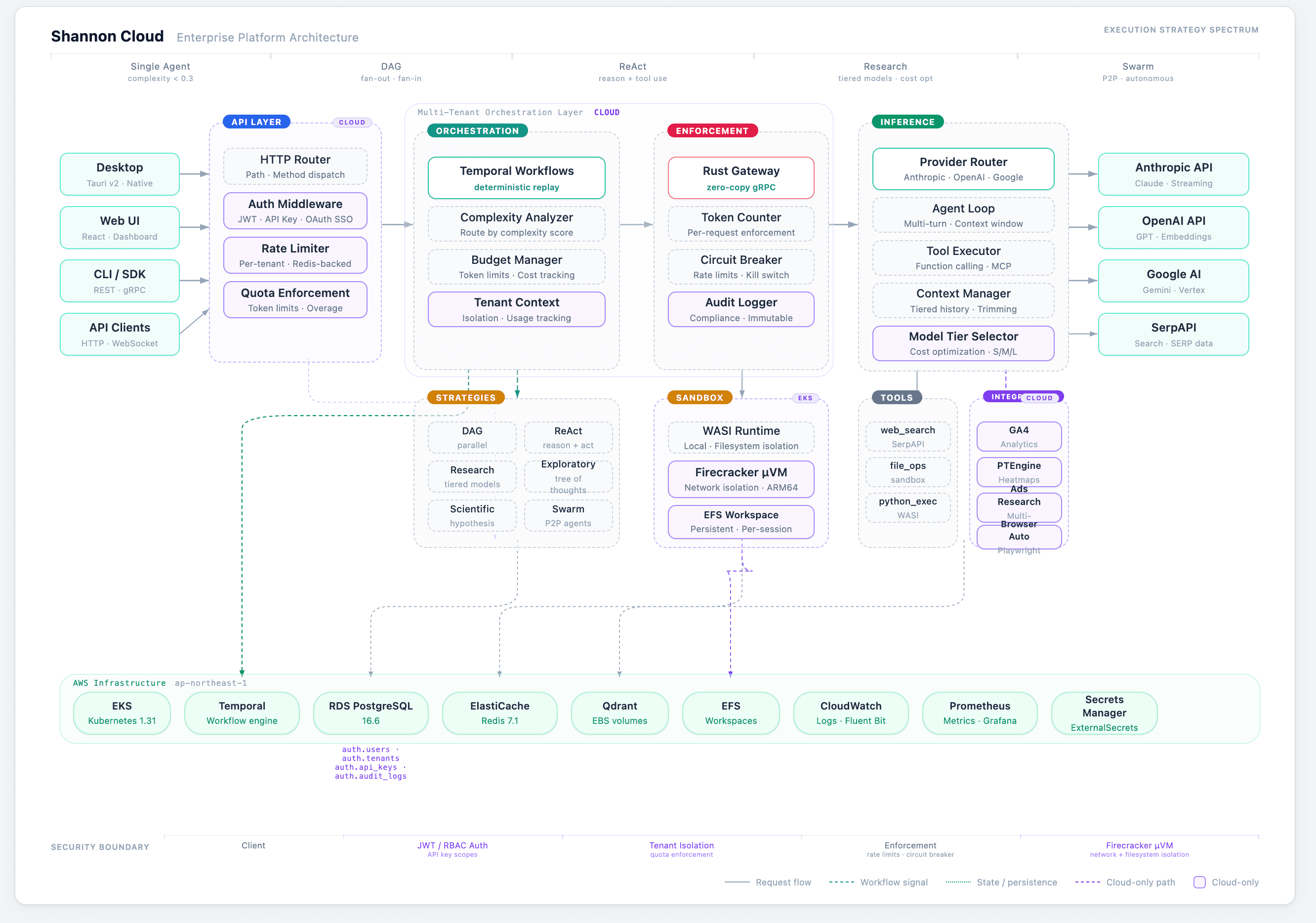
Go for Orchestration
The orchestration layer runs on Temporal, and Go is Temporal's native language. This choice gives Shannon:
- Deterministic replay: Every workflow execution is event-sourced. Export any failed workflow and replay it locally to reproduce bugs exactly.
- Durable execution: Tasks survive service restarts, network failures, and crashes. No lost work.
- Built-in retries: Automatic retry logic with exponential backoff, configurable per-activity.
- Workflow versioning: Deploy new workflow versions without breaking running tasks.
Unlike state machines or sequential execution in other frameworks, Temporal workflows are replay-safe by design. Every decision point is recorded. Every execution path is reproducible.
Rust for Security
The agent core handles security-critical operations where performance and safety are non-negotiable:
- WASI sandbox: Run untrusted Python code with no network access and read-only filesystem. WebAssembly's security model prevents escape.
- gRPC gateway: Sub-millisecond overhead for agent execution. Native code where latency matters.
- Policy enforcement: OPA (Open Policy Agent) integration for fine-grained governance.
Rust's memory safety guarantees eliminate entire classes of security vulnerabilities in the enforcement layer.
Python for LLM Integration
The LLM service stays in Python because:
- Provider ecosystem: Every LLM provider has a Python SDK. Fighting this is pointless.
- Rapid iteration: New models and tools appear weekly. Python's flexibility enables fast integration.
- MCP tools: Add tools via YAML configuration, no code changes required.
Shannon supports 15+ LLM providers including OpenAI, Anthropic, Google Gemini, DeepSeek, and local models via Ollama, LM Studio, and vLLM—with automatic failover between providers.
Solving Runaway Costs
Budget control isn't a feature in Shannon—it's infrastructure.
Hard Token Limits
Every task has an enforced budget ceiling. When the limit is reached, execution halts. No exceptions, no overruns.
The system tracks costs at multiple granularities:
- Per-task: Total budget for the entire workflow
- Per-agent: Individual agent token consumption
- Per-model: Cost attribution by provider and model tier
Automatic Model Fallback
When a task approaches its budget limit, Shannon can automatically fall back to cheaper models. A research task might start with Claude Opus for complex reasoning, then switch to Haiku for synthesis—all configured via policy, not code.
Real-Time Cost Attribution
Every workflow returns detailed cost breakdowns:
{
"usage": {
"total_tokens": 8547,
"cost_usd": 0.0127
},
"agent_usages": [
{ "agent_id": "research-coordinator", "cost_usd": 0.0031 },
{ "agent_id": "web-search", "cost_usd": 0.0051 },
{ "agent_id": "synthesis", "cost_usd": 0.0045 }
]
}Query costs by agent, model, or time range. Know exactly where your token budget goes.
Solving Non-Deterministic Failures
The hardest debugging problem in AI systems: reproducing failures in non-deterministic workflows.
Time-Travel Debugging
Shannon's Temporal foundation enables true workflow replay:
- Export: Capture the complete event history of any failed workflow
- Replay locally: Re-execute the workflow with identical inputs and decision points
- Step through: Examine every agent decision, tool invocation, and LLM response
- Fix and verify: Apply fixes and replay again to confirm resolution
No more "works on my machine" for AI workflows. Every production failure can be reproduced exactly.
Event-Sourced Execution
Every workflow decision is recorded as an event:
- Agent spawned
- Tool invoked with parameters
- LLM response received
- Budget checkpoint reached
- Approval requested/granted
This audit trail serves both debugging and compliance requirements.
Solving Security Vulnerabilities
Agents that execute code or call external APIs are attack vectors. Shannon treats this seriously.
WASI Sandbox
Python code execution runs in WebAssembly sandboxes:
- No network access: Code cannot make external API calls
- Read-only filesystem: Code cannot persist malicious payloads
- Memory limits: Prevent resource exhaustion attacks
- Execution timeout: Kill runaway processes
The sandbox is enforced at the WebAssembly runtime level—not by Python's trust model.
OPA Policy Governance
Fine-grained control over what agents can do:
- Which tools each agent can invoke
- Which external APIs are permitted
- Budget limits by user, tenant, or task type
- Human approval requirements for high-risk actions
Policies are defined declaratively and enforced consistently across all workflows.
Multi-Tenant Isolation
Enterprise deployments get complete tenant separation:
- Separate memory stores (Redis namespaces, Qdrant collections)
- Independent budget pools
- Isolated policy configurations
- Per-tenant audit logs
Intelligent Workflow Selection
Shannon doesn't require manual workflow construction. The orchestrator analyzes task characteristics and routes to the optimal execution pattern.
8+ Built-In Workflow Patterns
Core patterns:
- SimpleTask: Single-agent execution for low-complexity requests
- Supervisor: Coordinates multiple agents with dependencies
- Streaming: Real-time token streaming for interactive use cases
Cognitive patterns:
- DAG: Fan-out/fan-in parallel execution
- ReAct: Iterative reasoning with tool use
- Research: Multi-step research with citation filtering and gap detection
- Tree-of-Thoughts: Exploration for complex decision-making
- Scientific: Hypothesis testing with multi-perspective validation
The routing logic considers task complexity, dependency structure, and cognitive strategy requirements—then selects the appropriate pattern automatically.
Scheduled Execution
Production workloads often require scheduled tasks. Shannon supports cron-based scheduling with per-execution budget limits:
- Daily research digests
- Periodic data analysis
- Scheduled report generation
Each scheduled execution inherits the same budget controls and observability as interactive tasks.
Access Methods
Shannon provides multiple interfaces for different use cases:
OpenAI-Compatible REST API
Drop-in compatibility with OpenAI's API format at /v1/chat/completions. Existing applications can migrate without code changes.
Python SDK
Official SDK with CLI support for scripting and automation:
from shannon import ShannonClient
with ShannonClient() as client:
result = client.submit_task(
query="Analyze market trends",
cognitive_strategy="research"
)Native Desktop Applications
Pre-built applications for macOS, Windows, and Linux with system tray integration. Local-first interaction without browser dependencies.
Web UI
Development dashboard for workflow monitoring, cost analysis, and debugging.
Memory Architecture
Agents need both fast session memory and long-term recall. Shannon provides both:
Session Memory (Redis)
Fast, ephemeral storage for active conversations:
- Token usage tracking (prevent budget overruns mid-conversation)
- Recent message history
- Session metadata
Vector Memory (Qdrant)
Long-term storage for semantic recall:
- Similar workflow retrieval
- Cross-session context
- Diversity sampling to avoid redundant memories
Agents automatically query both stores based on context requirements.
Observability Stack
Production systems require production observability.
Real-Time Event Streaming
SSE endpoints stream execution events as they happen:
- Agent thinking states
- Tool invocations
- Decision points
- Completion status
Prometheus Metrics
Comprehensive metrics for monitoring and alerting:
- Task execution counts by workflow type
- Token usage by model and provider
- Latency percentiles (p50, p95, p99)
- Budget utilization rates
OpenTelemetry Tracing
Distributed tracing across all services. Every agent execution is a trace span, enabling end-to-end latency analysis.
Grafana Dashboards
Pre-built dashboards for cost monitoring, workflow performance, and system health.
Framework Comparison
| Capability | Shannon | LangGraph | CrewAI | AgentKit |
|---|---|---|---|---|
| Orchestration | Temporal (event-sourced, replay-safe) | State graphs (in-memory) | Sequential execution | Hosted platform |
| Workflow selection | Automatic (8+ patterns) | Manual graph construction | Manual role assignment | Visual builder |
| Deterministic replay | Full export/import | Limited (LangSmith) | No | Platform traces |
| Cost tracking | Per-agent, per-model attribution | Total only | Total only | Platform analytics |
| Code execution | WASI sandbox (isolated) | Jupyter kernel | No built-in | Code Interpreter |
| LLM providers | 15+ with auto-failover | OpenAI, Anthropic | OpenAI, Anthropic | OpenAI only |
| Local models | Ollama, LM Studio, vLLM | Limited | No | No |
| Scheduled tasks | Cron with budget limits | No | No | No |
| Desktop apps | macOS, Windows, Linux | No | No | No |
| Hosting | Self-hosted | Self-hosted | Self-hosted | Hosted only |
When Shannon Fits
- You need deterministic replay for debugging production failures
- You're running multi-agent workflows with complex dependencies
- You need per-agent cost attribution and hard budget controls
- You want to run local models alongside cloud providers
- You need to integrate proprietary APIs without forking the framework
- You want self-hosted infrastructure without vendor lock-in
When Alternatives Fit Better
- LangGraph: Rapid prototyping, Python-native workflows, LangSmith ecosystem
- CrewAI: Simple sequential agent patterns, minimal infrastructure
- AgentKit: Visual workflow builder, fully managed platform, no ops overhead
Design Philosophy
Shannon reflects several deliberate architectural choices:
1. Production-first: Every feature considers failure modes, cost implications, and security boundaries before convenience.
2. Right tool for the job: Three languages isn't complexity—it's using Go's concurrency for orchestration, Rust's safety for security, and Python's ecosystem for LLM integration.
3. Configuration over code: Adding providers, tools, and policies shouldn't require code changes. YAML configuration enables operational flexibility.
4. Observable by default: Every workflow produces cost data, execution traces, and audit logs. Observability isn't optional.
5. Self-hosted, no lock-in: Enterprise teams need to control their infrastructure. Shannon runs entirely on your hardware with no cloud dependencies.
Getting Started
Shannon is open-source under MIT license:
- Repository: github.com/Kocoro-lab/Shannon
- Documentation: Comprehensive guides in
/docs - Python SDK:
pip install shannon-sdk
The quickstart takes under 5 minutes with Docker Compose. For teams evaluating multi-agent platforms, Shannon offers a production-ready foundation without the typical prototype-to-production cliff.
If you're building AI agents and hitting the walls of cost control, debugging, or security—Shannon was designed for exactly these problems. Star the repo, try the demo, and open an issue with your use case.