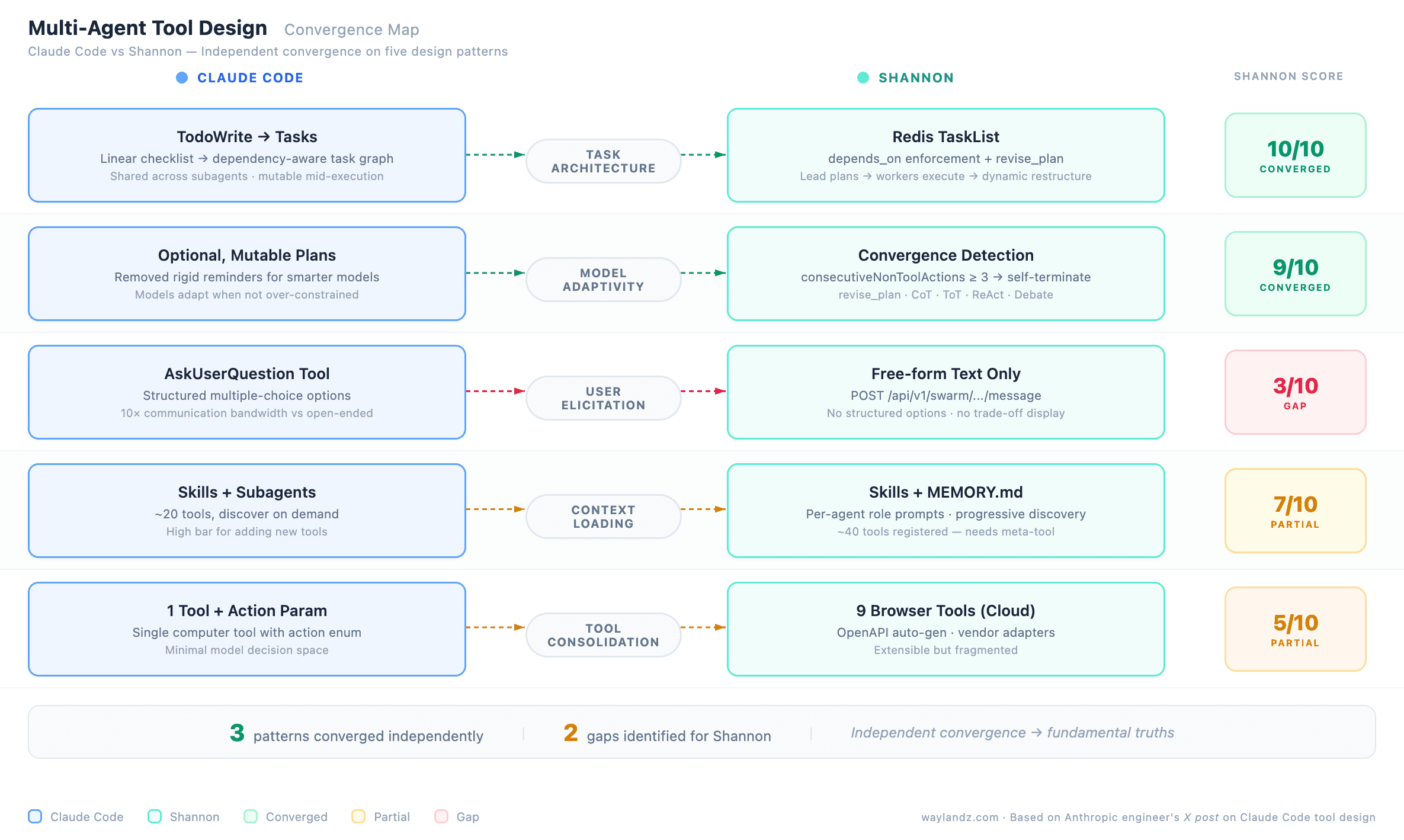
An Anthropic engineer recently described Claude Code's internal tool design evolution in an X post — from simple todo lists to dependency-aware task graphs with shared state across subagents. Reading it felt like reading Shannon's own architecture docs.
Shannon didn't get there first. But when independent teams converge on the same answers, those answers are probably fundamental truths. For readers new here: Shannon is a production-grade multi-agent platform built with Rust, Go, and Python. Shan is its CLI counterpart. What follows maps five lessons from Claude Code's evolution against Shannon's architecture — three validated, two that exposed real gaps.
Todos → Tasks: The Hardest Multi-Agent Problem
Claude Code started with TodoWrite — a linear checklist requiring system reminders every 5 turns to prevent plan drift. As models improved, Claude could recognize better paths mid-execution but felt obligated to follow the checklist. When subagents entered the picture, a shared linear list couldn't express dependencies or ownership. The solution was Tasks — dependency-aware, shared, mutable mid-execution.
Shannon arrived at the same design independently. Redis-backed TaskList with depends_on enforcement via taskHasUnmetDeps(). The Lead plans and assigns; workers execute and report; the Lead can call revise_plan to restructure dynamically. A shared workspace lets agents publish findings visible to all teammates. Near 1:1 match — the strongest convergence point.
Don't Over-Constrain Smarter Models
Tools that helped weaker models can actively harm stronger ones. Claude Code found that reminding the model of its todo list made it stick rigidly to plans instead of adapting. The fix: make the system optional and mutable.
Shannon accounts for this through convergence detection (consecutiveNonToolActions >= 3) — agents self-determine when they're done rather than following rigid step counts. revise_plan is the escape hatch, and cognitive pattern auto-selection (CoT, ToT, ReAct, Debate) adapts reasoning to the problem. Takeaway: audit your agent prompts as models improve. What guided GPT-4 may be a straitjacket for Opus 4.
Structured Elicitation > Free-form Questions
Claude Code tried embedding questions in plan output (confused the model), modified markdown (unreliable parsing), and finally a dedicated AskUserQuestion tool with structured multiple-choice options. The third worked — structured options dramatically increased communication bandwidth.
Shannon's biggest gap. Human-in-the-loop is free-form text only. What it needs: an ask_user action sending structured options via SSE. The difference between "What should I do?" and presenting three specific options with trade-offs turns human-in-the-loop from a bottleneck into a force multiplier.
Progressive Disclosure for Agent Context
Don't dump everything into the system prompt. Let agents discover context through search and skill files. Keep the action space small (~20 tools) and use subagents for specialized knowledge.
Shannon validates this. Skills load knowledge on demand. MEMORY.md indexes topic files — progressive discovery. Per-agent role prompts load individually, not monolithically. But Shannon has a gap on tool count: ~40 registered versus Claude Code's ~20. Even with role-based filtering, some roles see 8-9 tools. Shannon needs dynamic tool discovery — a meta-tool listing available tools on demand.
Tool Design Must Match Model Capabilities
Each new tool is one more option the model evaluates every turn. Prefer extending existing tools over adding new ones.
Shannon's browser architecture illustrates this: cloud has 9 separate tools, CLI has 1 with an action parameter — matching Claude Code's single computer tool approach. Cloud needs the same consolidation. Shannon's advantage is extensibility without tool explosion: OpenAPI adapters auto-generate tools from spec URLs, and vendor adapters handle API quirks without expanding the model's decision space.
What This Means
Three independent convergences: dependency-aware tasks, model-adaptive design, progressive disclosure. Two clear gaps: structured elicitation (3/10) and tool count discipline (5/10).
When independent teams solve the same hard problems and arrive at the same patterns, those patterns are probably fundamental truths of multi-agent design. The actionable takeaway: as models get smarter, periodically audit whether your tools are over-prescriptive.
Production-Grade Multi-Agent Platform — Built with Rust, Go, and Python
Shannon CLI — Local computer use and multi-agent orchestration